説明
[ブースティング]
Boostingについて
Boostingとは、教師有り機械学習を実行するための機械学習メタアルゴリズムです。つまり、一般の機械学習を より精度良く実行するためのフレームワークと言えます。Boostingで構築される識別器の概念を以下に示します。
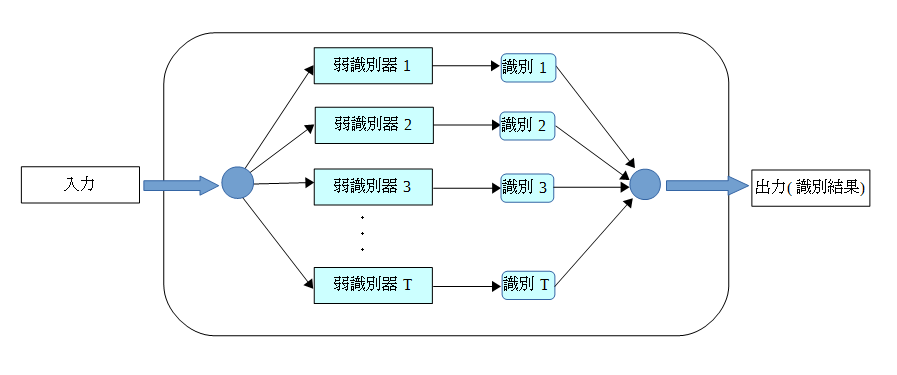
Boostingは、複数の弱い学習機をまとめ、その結果に重みを付けて足し合わせることで、 一つの強い学習機を構築することを目的とします。ここで、弱い学習機とは、識別の正解確率がまったくの 当てずっぽう(つまり正解確率が50パーセント)なものよりも性能がよいだけの、非常にシンプルなものとなります。 しかし、多数の弱い学習機を多数作成し、組み合わせて用いることで、強力な強い学習機を作成することができます。 一般に、作成される弱い学習機は「弱識別器」、最終的に構成される強い学習機は「強識別器」と呼ばれます。
弱識別にどのような機械学習アルゴリズムを用いるかは特に制限はありません。本ライブラリでは、Boostingの実装として、 代表的な弱識別器の一つである決定株(=高さ1の決定木)を用いた、AdaBoostの学習を実装しています。
また、本ライブラリの実装は、2クラス識別にのみ対応をしており、3クラス以上の識別には対応していません。
AdaBoost
AdaBoost(アダブースト)は、Boostingの枠組みの中でも最も代表的なアルゴリズムです。AdaBoostの基本的な処理は以下のようになります。
1: 各教師データの重みを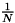 に初期化する。(ここで
に初期化する。(ここで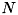 は教師データの個数とします)
は教師データの個数とします)
2: 弱識別器を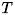 個作成するとする
個作成するとする
3: 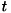 番目(
番目(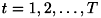 )番目の弱識別器を学習する。学習は重みつきの教師データを用いて、誤り率が最小となるように行う
)番目の弱識別器を学習する。学習は重みつきの教師データを用いて、誤り率が最小となるように行う
4: 各教師データへの重みを更新する。重みは弱識別器の誤り率を用いて以下のように行う
- 弱識別器が誤って識別したデータ → 重みが高くなるように更新
- 弱識別器が正しく識別したデータ → 重みが低くなるように更新
6: 個の弱識別器が作成されるまで、3,4,5を繰り返す
AdaBoostは、与えられた各教師データに対して重み付けを行い、その重みを適応的に変化させながら、 逐次的に弱識別器を学習・作成していきます。弱識別器は、重み付けされた教師データに対して、 誤り率(=誤識別をした教師データの重みの和)が最小となるように学習されます。そして、ある弱識別器が 誤識別をした教師データは重みを増し、正しく識別をした教師データは重みを小さくします。そして、その 重み分布の元で、次の弱識別器を学習します。
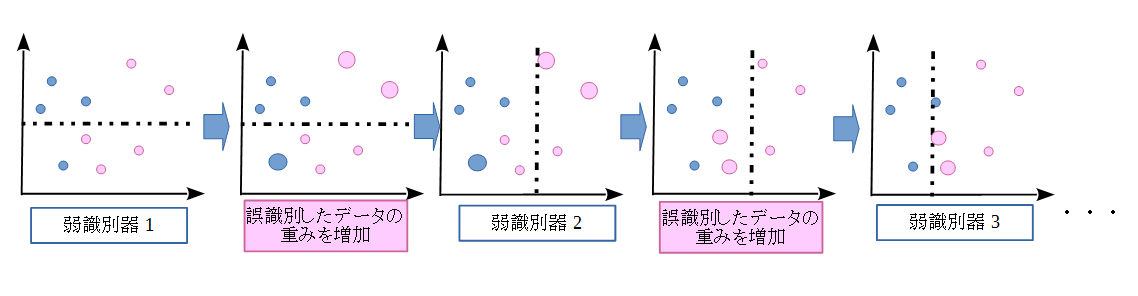
このように、各教師データの重みを、作成した弱識別器の識別性能に応じて適応的に変化させる事で、 ある弱識別器が苦手とする教師データを、次の弱識別器は優先して正しく識別できるようになります。
(互いに欠点を補い合えるような弱識別器を作成していく、と考えてもよいでしょう)
識別を行うときは、各弱識別器の出力を元に多数決をとり、その符号の正負で2クラスのどちらであるかを識別します。
本ライブラリでは、AdaBoostの枠組みとして、以下のアルゴリズムを実装しています。
- Discrete AdaBoost
- Real AdaBoost
- Discrete AdaBoost
- Discrete AdaBoostは、AdaBoostの中で最も標準的なアルゴリズムです (一般にAdaBoostというと、このDiscrete AdaBoostを指します)。 Discrete AdaBoostは、+1, -1の二値の出力と、その識別の信頼度をもつ弱識別器で構成されます。 弱識別器の選択は、教師データに対する重みつきの誤識別率、つまり誤識別をした教師データに付与されている 重みの和が最小となるものを選択します。
強識別器の出力は、各弱識別器の出力に、信頼度を乗じた値の和で出力され、その値の符号で識別を行います。
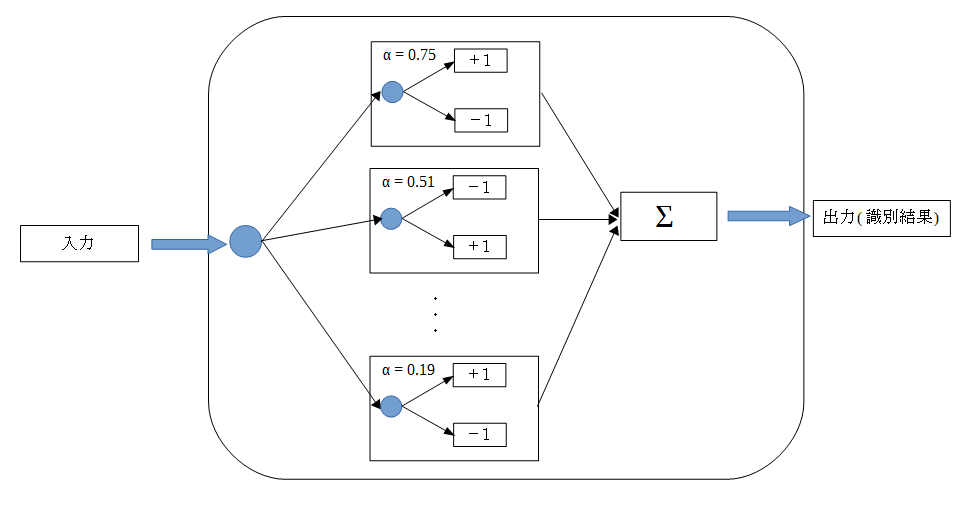
- なお、弱識別器の選択の結果、選択された弱識別器の重みつき誤り率がちょうど0.5(=50%)となった場合は、 この時点で学習を打ち切ります。 これは、アルゴリズム上、誤り率が0.5となってしまった場合は、重みの更新が出来なくなってしまうためです。
- Real AdaBoost
- Real AdaBoostは、R.E.Schapireらが発表した、AdaBoostの派生系のアルゴリズムです。Discrete AdaBoostの弱識別器は、 +1, -1の二値出力と、その識別の信頼度で構成されていますが、Real AdaBoostでは、弱識別器の出力を、特徴量の 確率密度分布に応じて多値化します。つまり、各特長量の重み付分布をクラス毎にヒストグラムとして表し、 その二つのヒストグラム間の分離の度合いを出力とします。
弱識別器の選択は、2つのヒストグラムの類似度を示す距離であるBhattacharyya距離(バタチャリア距離)が、 最も大きなもの(最も離れているもの)を選択します。
強識別器の出力は、各弱識別器が出力する出力値の線形和で出力され、その値の符号で識別を行います。
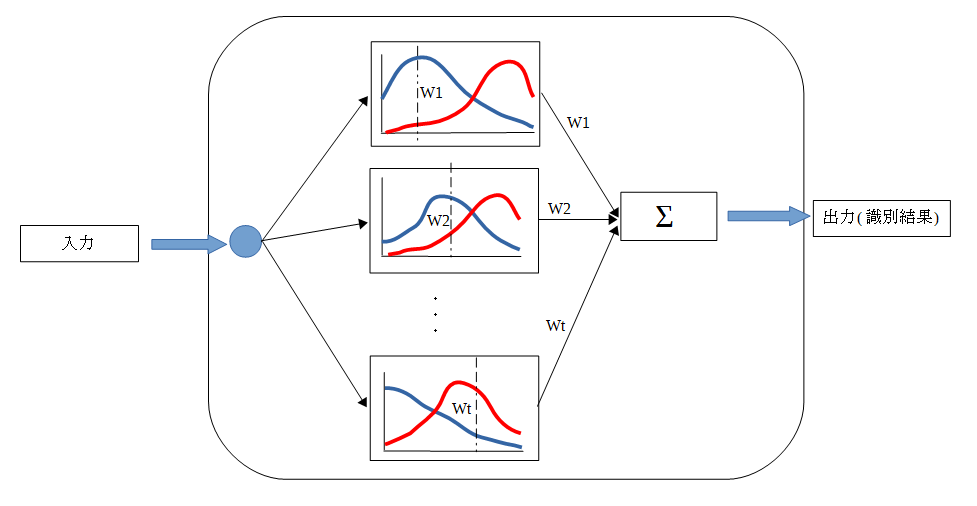
- Real AdaBoostはサンプルに対してどの程度の識別が可能であるかがわかるため、効果的な重みの更新が可能であり、 Discrete AdaBoostに比べて学習の収束が早く、少ない弱識別器で高精度な識別が可能です。
カテゴリ属性と数値属性の扱い
AdaBoostでは、入力の特徴ベクトルの属性として、「数値属性」と「カテゴリ属性」を扱うことができます。
数値属性とは、特徴ベクトルの各値が連続変数、つまり2つの異なる値が数値として比較可能なものであることを意味します。 例として、"画素の濃度"や"対象物の面積"のように、具体的に数値として観測されたものが当たります。
カテゴリ属性とは、特徴ベクトルの各値が、離散的なクラスラベルを示す値であることを意味します。 例として「矩形 = 0」「円 = 1」「楕円 = 2」のように、特定の属性を数値と対応させ、その属性を示す ラベルとしたものが当たります。
なお、カテゴリ属性のベクトルを扱う場合、特徴ベクトルの各値は全て整数値である必要があります。
Boostingのパラメータ
Boostingで必要となるパラメータを説明します。
- 特徴ベクトルの属性
- 入力された教師データの特徴ベクトルが、数値属性であるか、カテゴリ属性であるかを指定します。 数値属性を指定した場合は、教師データの各値を連続的な数値として扱います、 カテゴリ属性を指定した場合は、特徴ベクトルの各値を、離散的なラベルとして扱います。
なお、カテゴリ属性を指定する場合は、特徴ベクトルの値は全て整数値である必要があります。 そのため、小数点以下の値が含まれていた場合は、小数点以下の値は内部で強制的に切り捨てられ、 整数値に変換されます。つまり、カテゴリの区別は全て整数値部分の値のみで行われます。
- Boostingのタイプ
- 学習で用いるBoostingのタイプを指定します。指定できるパラメータは以下のようになります。
- F_BOOST_TYPE_DISCRETE : Discrete AdaBoostによる学習を行います。
- F_BOOST_TYPE_REAL : Real AdaBoostによる学習を行います。
- 弱識別器の数
- 強識別器を構成する、弱識別器の数を指定します。強識別器を構成する弱識別器の数が この値に達した場合、学習を終了します。
- 学習を終了する誤識別率
- 学習を終了する、教師データに対する強識別器の誤識別率を指定します。
学習中、弱識別器を追加する度に、教師データに対する現在の強識別器の性能(誤識別率)を計算し、 その値がパラメータで指定した値以下になった場合は学習を終了します。
F_ML_BOOST_STOPRATE_INVALIDを指定した場合は、誤識別率による停止判定は行わず、 指定された弱識別器数に達するまで学習を続けます。
- 事前処理
- 学習を開始する前に、与えられた教師データに行う前処理を指定します。 指定可能な事前処理は以下のものになり、これらは組み合わせて同時に指定可能です。
- 重複した教師データの削除
入力された教師データの中で、特徴量がまったく同じデータが複数存在したときに、以下のルールに従って データを削除します。- 同一クラス内の重複データ :クラス内に一つだけ残るようにして、他を全て削除します。
- 複数クラス間での重複データ:「矛盾データ」と判断して、全て削除します。
- データの正規化
教師データとして与えられた特徴ベクトルの各成分ごとの最大値・最小値を探索し、その値で 全ての特徴ベクトルを [-1.0, 1.0] の範囲に正規化します。入力される特徴ベクトルが極めて小さい場合など、 数値計算上の誤差が考えられる場合、正規化を行うことで、これを回避するなどの効果が期待できます。
- 教師データの特徴ベクトルがカテゴリ属性で合った場合は、事前処理の指定は無視されます。これは以下の理由によります
- 特徴ベクトルの値は属性を示すラベルを意味し、数値的な意味を持たない
- カテゴリ属性の場合は、重複性は分岐を決定する上でむしろ情報となるため
- 学習時間
- 学習を行う時間の上限を秒単位で設定します。教師データの内容や、パラメータ の指定によっては、学習に極端に時間がかかる場合があります。このパラメータで学習に用いる時間の 上限を設定しておくと、学習の終了条件を満たす前であっても学習を打ち切ります。 値を0にすると、終了条件を満たすまで学習を続ける設定になります。
その他
- Boostingの特徴:
- Boostingの特徴として、以下のものが挙げられます。
- 調整するパラメータ数が少ない
他の機械学習に比べ、設定するパラメータが少なく、調整や評価が容易です。
- 過学習を起こしにくい
Boostingの識別性能は、構成する弱識別器の数に依存します。このとき、弱識別器の数を多くしていっても、 教師データに対する過学習が起きにくいことが示されています。そのため、ある程度大雑把な設定であっても 識別性能がさほど低下しません。
- ノイズや、はずれ値の影響を受けやすい
Boosting(AdaBoost)は、作成した弱識別器の誤識別に応じて、教師データの重みを変化させます。 そのため、教師データのはずれ値や、ノイズに対しても適応をしようとするため、結果的に識別性能に影響を 受けやすいという性質があります。
- Discrete AdaBoostの学習結果:
- Discrete AdaBoostで学習を行った結果、弱識別器の数が指定数よりも少なく、かつ識別性能が高くないケースがあります。 これは、先の説明でもあったように、弱識別器の学習を行った結果、重み付き誤り率がちょうど0.5であるような弱識別器しか 作成できなくなった場合、重みの更新の計算が不可能となるために発生します。
このような状態になった場合は、以下の事を検討してください。- Real AdaBoostを使用する
- 教師データの数を増やす・特徴量を見直す
- 他の機械学習を用いる
- 参考文献:
- [1]C.M.ビショップ. パターン認識と機械学習 -ベイズ理論による統計的予測(下). 元田 浩 他 監訳 . 丸善出版. 2008. 433p
- [2]三田 雄志. "AdaBoost". コンピュータビジョン最先端ガイド1. 八木 康史 他 編著. アドコムメディア株式会社. 2008. p.132-154
- [3]R.E.Shapire, Y.Singer. 'Improved Boosting Algorithms Using Confidence-rated Predictions'. Machine Learning, 37, pp297-336,(1999)