説明
[機械学習]
機械学習ライブラリについて
本ライブラリは、機械学習の「教師あり学習」の機能を提供するライブラリです。機械学習とは、歴史的には、 人工知能の研究分野の中で、人間が、日々得ている実体験の情報の中から再利用できそうな知識を取得していく、という 過程をコンピュータで実現したいという動機から生まれました。現在では、数値・文字・画像・音声など、多種多様な データの中から、規則性・パターン・知識を発見し、現状の把握や未知の状況への予測をするのに役立てることが目的と なっています。
- 教師あり学習
- 「教師あり学習」とは、入力データとそれに関連する学習すべき付随情報(クラス毎に付けられたラベルや観測した数値)が 共に与えられ、付随情報が無いデータを与えられたときに、対応する付随情報を予測するための規則等を 取得する学習のことです。つまり、データと付随情報のペアを「入力と答えの例題(=教師からの助言)」とみなして、 それをガイドとして学習を行うというものです。
- 教師データ
- 学習のために事前に与えられる例題を「教師データ」と呼び、数学的な定義としては、ベクトルとラベルの組と して、
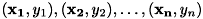 のように与えられます。 これは「入力が
のように与えられます。 これは「入力が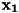 のときの答えは
のときの答えは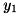 , 入力が
, 入力が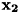 のときの答えは
のときの答えは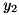 」 のような例題集と考えることもできます。
」 のような例題集と考えることもできます。
ベクトル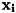 は、学習したい対象の特徴を現すデータとなるため、「特徴量」または「特徴ベクトル」と いいます。
は、学習したい対象の特徴を現すデータとなるため、「特徴量」または「特徴ベクトル」と いいます。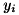 は、が分類上どのクラスに属するかを示すための離散的な値をとります。 通常、この数値は人間がラベル付けすることで提供されることが多いので、単にラベルとも呼ばれます。
は、が分類上どのクラスに属するかを示すための離散的な値をとります。 通常、この数値は人間がラベル付けすることで提供されることが多いので、単にラベルとも呼ばれます。
- note
- がラベルではなく観測データなどの実数値の場合は、入力に対する数値を予測する 学習になります。これを回帰問題といいますが、現段階では、本ライブラリでは回帰問題には対応していません。
教師データオブジェクト・学習オブジェクト
実際に機械学習を行い、その学習結果を用いて識別(入力データに対する予測)を行うには
- 大量の教師データの管理
- 学習した結果、得られた情報の保持と、その情報による識別処理
が必要になります。本ライブラリでは、この「大量の教師データの管理」「学習した結果の保持」のために、 「教師データオブジェクト」「機械学習オブジェクト」を用います。
- 教師データオブジェクト
- 教師データオブジェクトは、実際に教師データ(特徴ベクトルとクラス付けをするラベル番号) を内部に保持するオブジェクトです。また、扱う特徴ベクトルの次元数、保持している教師データの データ数等もあわせて保持しています。ユーザは、この教師データオブジェクトに対して、 関数を通じて教師データの追加・操作を行います。そのため、大量の教師データ作成に伴うデータ管理や データ増加に伴うメモリの管理を気にする必要はありません。
- 機械学習オブジェクト
- 機械学習オブジェクトは、学習を行った結果得られる、識別のための様々な情報を保持するオブジェクトです。 機械学習のアルゴリズムは様々なものが提案されており、学習の結果得られる情報や、 学習の際に渡されるパラメータについてもアルゴリズム毎に異なります。また、識別を行うための 内部的な処理もアルゴリズムによって大きく異なってきます。
このような、学習アルゴリズムの違いを吸収し、学習結果を統一的に扱えるように、学習した結果は 機械学習オブジェクトという形で出力・保持されます。機械学習オブジェクトは、学習によって得られた 結果や、学習のパラメータといった情報をカプセル化し、学習アルゴリズムの違いを抽象化して保持します。 実際の識別の際には、機械学習オブジェクトを用いる関数を用いれば良いので、ユーザはどのようなアルゴリズムで、 学習が行われたか、識別はどのような処理で行うかを意識する必要がありません。
処理の流れ
実際に本ライブラリを用いて機械学習を行い、その結果を用いるまでの流れを示します。機械学習は大まかに 「教師データの準備と学習」「学習結果を利用した予測」の2ステップの流れになります。
- 教師データの準備と学習
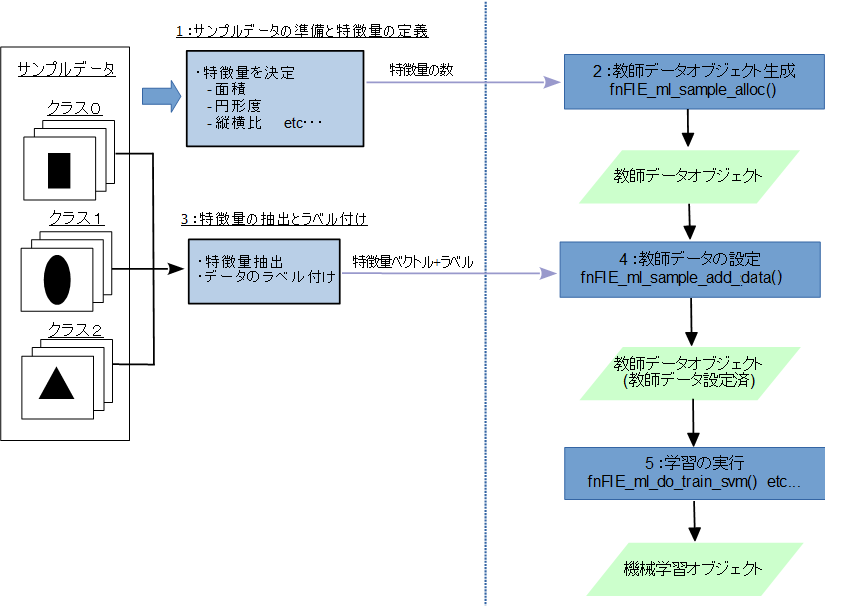
- 1 :サンプルデータの準備と特徴量の定義
正しい分類結果が既知のデータセットを用意し、これらのデータをクラス別に識別・特定するための特徴量を定義します。 対象とするデータによって、特徴量の選択や組み合わせは無数に存在しますが、この特徴量が学習の識別精度を上げる上で 最も重要な要素の一つとなります。対象となるものがどのようなものか、各クラスでどのような違いがあるか、 などをチェックし、適切な特徴量を選択してください。
- 2 :教師データオブジェクトの生成
fnFIE_ml_sample_alloc() で教師データオブジェクトを作成します。このとき、1で定義した特徴量の数(=特徴ベクトルの次元) もあわせて指定します。
- 3 :特徴量の抽出とラベル付け
用意したデータセットから特徴量を抽出し、クラスラベルと併せた教師データとします。 特徴量は1で定義したものになります。また、クラスラベルはデータ毎に既知のものを用います。
- 4 :教師データの設定
教師データオブジェクトに教師データを設定します。 教師データの設定は fnFIE_ml_sample_add_data() を用います。
- 5 :学習の実行
教師データを設定した教師データオブジェクトを用いて学習を行います。学習を開始する 関数は、学習アルゴリズム毎に用意されていますので、それらの中から選択し、学習を実行してください。
(例:サポートベクターマシン -> fnFIE_ml_do_train_svm() )
- 学習結果を利用した予測
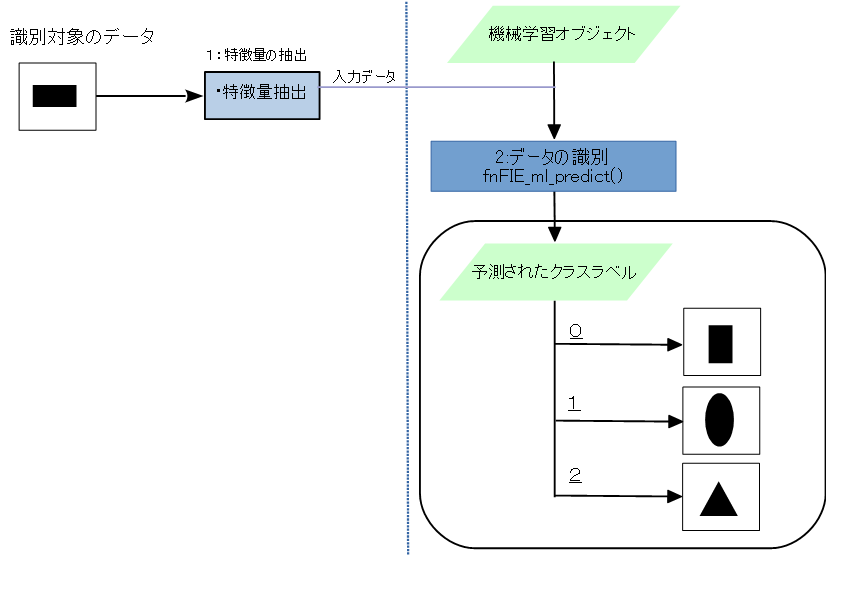
- 1 :対象データの特徴量抽出
識別を行う対象のデータから、学習で用いた特徴量と全く同じ特徴量を取得します。
- 2 :データの識別 1で取得した特徴量と、機械学習オブジェクトを用いて識別を行います。 識別は fnFIE_ml_predict() で行います。
識別の結果は、予測されたクラスのラベルで出力されます。
学習アルゴリズム
本ライブラリでは、現在以下の学習アルゴリズムを実装しています。アルゴリズムによって、学習の特性や学習時の制限事項などが異なってきます。詳しい内容については 各アルゴリズムのドキュメントを参照してください。
その他
- 誤識別が多発する場合
- 教師データの数が十分ではない可能性があります。サンプル数の追加を検討してみてください。
- 教師データに極端な偏りがないか確認してください。異なるラベルを持つデータ間のデータ数の偏りはもちろんですが、 同じクラスラベル内のデータでも、実はほとんど同じようなデータばかりを集めている場合もあります。同じクラスに含まれる 範囲で、データを広く選択してみてください。
- 学習を行うときのパラメータを調整します。一般的に、パラメータの設定が学習すべき内容と 合致していない場合、学習の精度は悪くなり、場合によってはほとんど分類できないようなケースに陥ることもあります。 パラメータの内容については、各学習アルゴリズムのドキュメントを参照してください。
- 使用する特徴量を再検討します。特徴量は識別精度を決定付ける重要な要素です。 異なるクラス間で確実に異なる(=各クラスの特徴を決定付ける)特徴量を選択してください。
- 学習に時間がかかる場合
- 学習を行うときのパラメータを調整します。パラメータによっては与えられた教師データに対して 過剰に適合しようとして、学習に時間がかかる場合があります。学習の拘束性を緩めるように、パラメータを 調整してみてください。
- 教師データの数が過剰である可能性があります。データに偏りがでないようにしながら、データ数を削減してください。 その上で、満足するような識別精度が出なかった場合に、データ数を増やしていくと良いでしょう。
- 教師データ内に重複したデータがないか確認をして下さい。特に、特徴量の値がまったく同じであるのに、異なる クラスに属するような教師データは、どちらに分類されるかがはっきりしない矛盾したデータになり、学習時間を 増加させる原因となります。本ライブラリでは、学習開始時の前処理として、このような重複データをトリムする 機能も実装していますので、そちらも試してみてください。
- 使用する特徴量を再検討します。機械学習においては、対象とする空間(=特徴量の次元)が増加すると、 学習に必要な計算量が指数的に増加していく「次元の呪い」というものが知られています。 使用している特徴量の中に、クラス間の識別に無意味な特徴や、ほとんど寄与しない冗長な特徴が 含まれていないか確認をして下さい。
- 使用例
- サンプルコード
- 参考文献:
- [1]C.M.ビショップ. パターン認識と機械学習 -ベイズ理論による統計的予測(上). 元田 浩 他 監訳 . 丸善出版. 2007. 349p
- [2]C.M.ビショップ. パターン認識と機械学習 -ベイズ理論による統計的予測(下). 元田 浩 他 監訳 . 丸善出版. 2008. 433p