- HOME
- 【工場DX】予知保全に最適なAIを見極める アルゴリズム選択の勘所
生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極める
アルゴリズム選択の勘所

現在、様々な分野で活用が進んでいるAI。製造業の現場では、設備の状態監視の強化として予知保全を実現するためにAIの活用が検討されています。AIには、従来の機械学習と深層学習(ディープラーニング)があります。「画像データでは、ディープラーニングの活用例が多くみられるが、センサーデータやログデータのような時系列データでもディープラーニングが最良な選択肢なのか?」という疑問をよく耳にします。予知保全への利用は従来の機械学習とディープラーニングのどちらを選択するのがよいのでしょうか。
本特集では、そんな疑問に対してデータの視点、アルゴリズムの視点、使い勝手の視点など、実際のデータ検証も踏まえ、3回に分けてお答えします。第1弾は、「アルゴリズム選択の勘所」です。
第1弾:「アルゴリズム選択の勘所」
第2弾:「データ検証によるコスト比較」
第3弾:「AIの実導入における課題とソリューション」

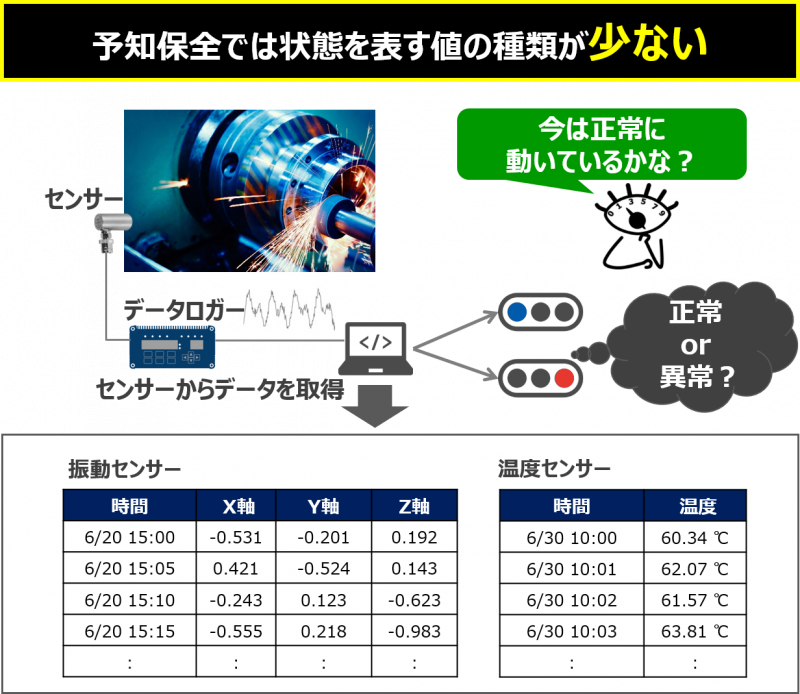
予知保全で使用するデータとは
実業務でのAI活用を検討するには、扱うデータを理解し特徴を捉えることがとても重要です。昨今活用が進んでいるAI技術であるディープラーニングは、画像の物体認識の例が取り上げられることが多いですが、予知保全の領域ではどのようなデータを扱うことが多いでしょうか?
予知保全においては、主に設備や装置に取り付けたセンサーから取得した「時系列データ」を扱います。
例えば、振動センサーであればXYZ軸の値の3種類、温度センサーであれば、温度値の1種類のデータで状態を表します。また、予知保全のゴールは、設備の状態が「正常かどうか」を捉えることです。つまり、判断したいものが「正常」と「異常」の2種類の非常に少ないデータと言えます。
一方、画像の物体認識においては、画像データをピクセル単位に分割し、色情報をRGB値のマトリクス情報に変換した大量のデータを扱う必要があります。また、画像に映っているものが何かを判断するため、判断したいものが多岐に渡り、膨大な数となります。
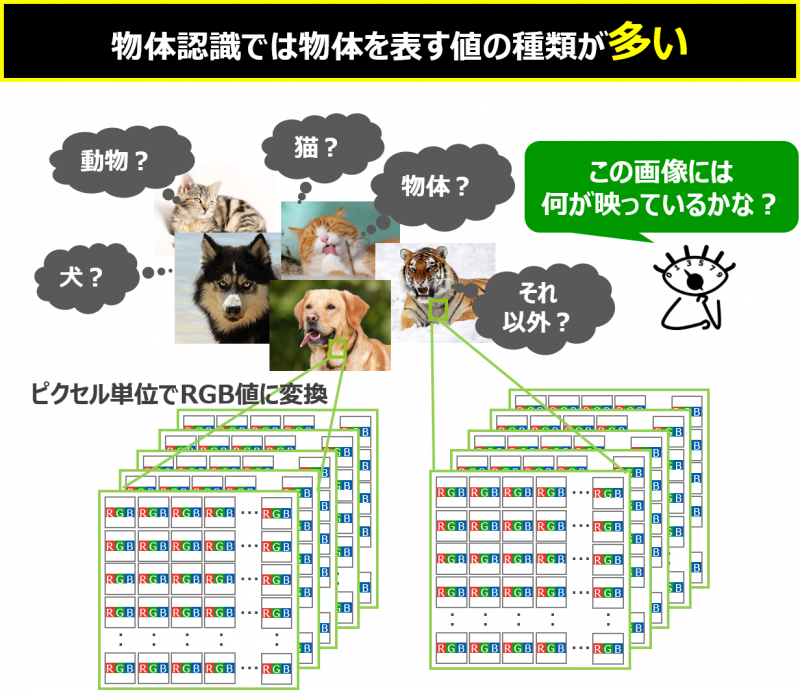
つまり、予知保全で扱う時系列データは物体認識と比較すると、読み取るデータの種類と判断したいことの種類が非常に少ないデータと言えます。
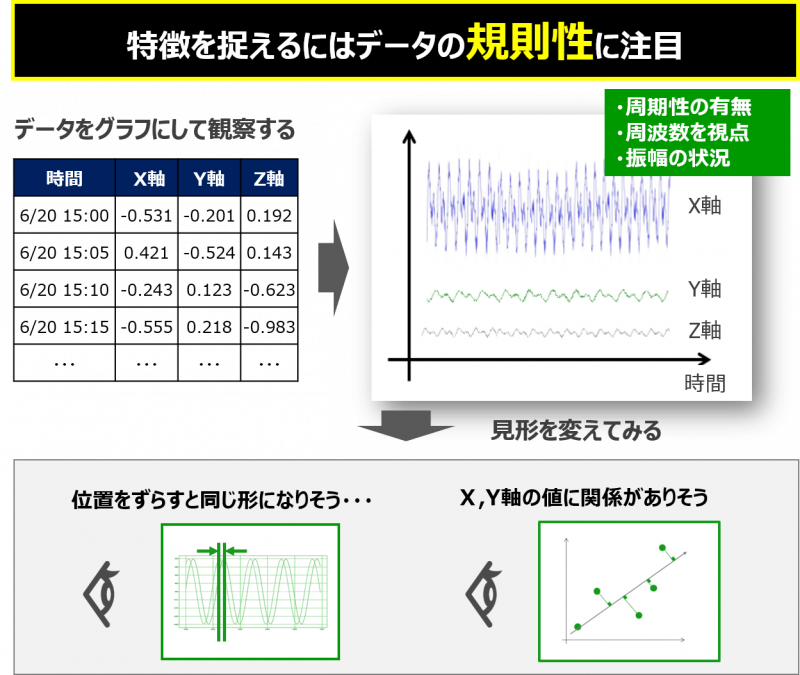
時系列データの特徴
時系列データには、一定時間で規則性があるという特徴があります。そのため、見るべきポイントを人がある程度決めやすいデータになります。この規則性に注目すると、周期や周波数、振幅、値の平均やばらつき方等、旧来の数学や統計的手法で特徴を数値化することができます。
一方で、画像の物体認識の例ではどうでしょうか?画像データの特徴を捉えるには、画像の線や角度、色の特徴を抽出して数値化し、各画像に似た箇所がないかを比較します。例えば、動物を認識したい場合は、「耳」や「目」の形状を特徴として抽出し、数値化します。しかし、少量のデータでは例外を捉えにくく(ex.狼の画像を犬と認識してしまう)、特徴を捉えるには大量のデータが必要になります。また、画像データでは、画像ごとに角度のや画像の欠けなどの違いがあるため、より規則性が乏しくなります。

機械学習とディープラーニング
時系列データを活用してAIを実装するには、大きく分けて従来の機械学習とディープラーニングの2種類のアルゴリズムがあります。2つの最も大きな違いは「特徴を捉えること(特徴抽出)」を人が行うかどうかです。従来の機械学習では、特徴抽出は人が行い、その結果をもとに機械がデータの学習を行います。このため、特徴抽出を人が行いやすく、取得できるデータ量が少ないデータが向いています。ディープラーニングでは、機械自身が特徴そのものを学習します。そのため、人が特徴抽出を行うことが難しく、大量データを取得できるようなデータに向いています。
【従来の機械学習】

【ディープラーニング】

そのほかに、従来の機械学習とディープラーニングには、主に以下の表のような違いがあります。
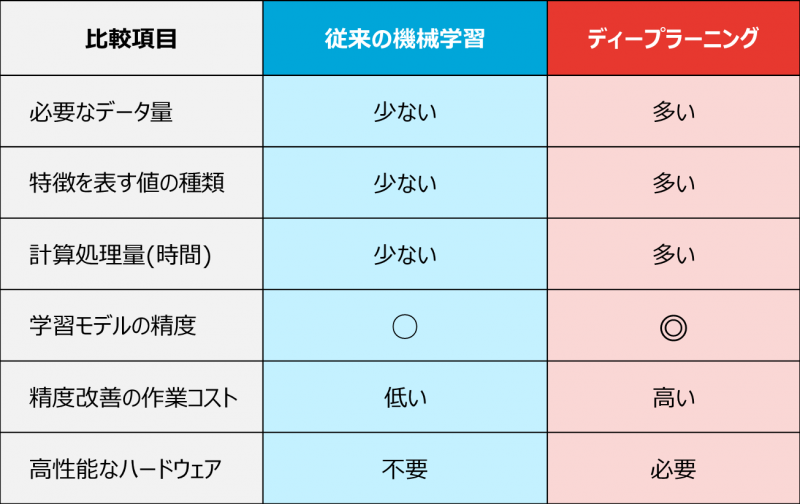
では、この違いをAIを導入する際のコストバランスの視点で比較してみましょう。
従来の機械学習は、特徴抽出を人が行うため、その設計と調整にコストがかかる傾向があります。一方、ディープラーニングは、機械が学習する範囲がより広いため、学習モデルの開発や精度改善のコストが大きくなります。また、大量データを扱う必要があることから、高い計算処理能力を求められます。
これらをトータルで見ると、ディープラーニングの方がよりコストがかかる傾向にあります。
【従来の機械学習とディープラーニングのコストバランス比較】

予知保全のアルゴリズム選択
従来の機械学習とディープラーニングのどちらのアルゴリズムを選択すべきかは、扱うデータの特徴や解決したい業務課題の内容、誰がデータを取得してAIを使うかによっても異なってきますので、アルゴリズムの適性を見極めることが重要です。
予知保全においては、データの特徴を人が捉えられることが多く、取得できるデータ量も少ないケースが多くあります。そのため、コストバランスの視点では、従来の機械学習の手法でも十分に業務課題の解決が可能なケースが多いと考えられます。
【1. 現場業務とデータの理解】
予知保全の領域でAIを適用したい現場の業務において、どのような特徴のデータを取得できるか、どの程度のデータ量を取得できるかを理解し、明確にすることが重要です。予知保全の領域のデータは他の領域と比較すると、規則性を捉えやすい特徴があり、データ量は少ない傾向にあります。
【2. アルゴリズムの適性】
従来の機械学習とディープラーニングのいずれのアルゴリズムにおいても、両者の特徴や違い、コストバランスを理解した上で、アルゴリズムを選択することが重要です。また、併せて現場の業務や取得したデータについて理解している必要があります。一般的に、従来の機械学習よりもディープラーニングの方が、トータルのコストがかかる傾向にあります。
【3. 対象ユーザー】
業務のどのような関係者がデータを取得し、AIを導入、利用するかという視点も大切です。これらの作業には工数を要しますので、工数を適切に見積もる必要があります。また、実際の運用においては、データ分析担当者だけでなく、現場の業務担当者も扱うことを求められることが多いため、ユーザーが理解しやすく、業務で扱いやすいものであることが必要です。

