製品・サービス
時系列データ自動分析マシン

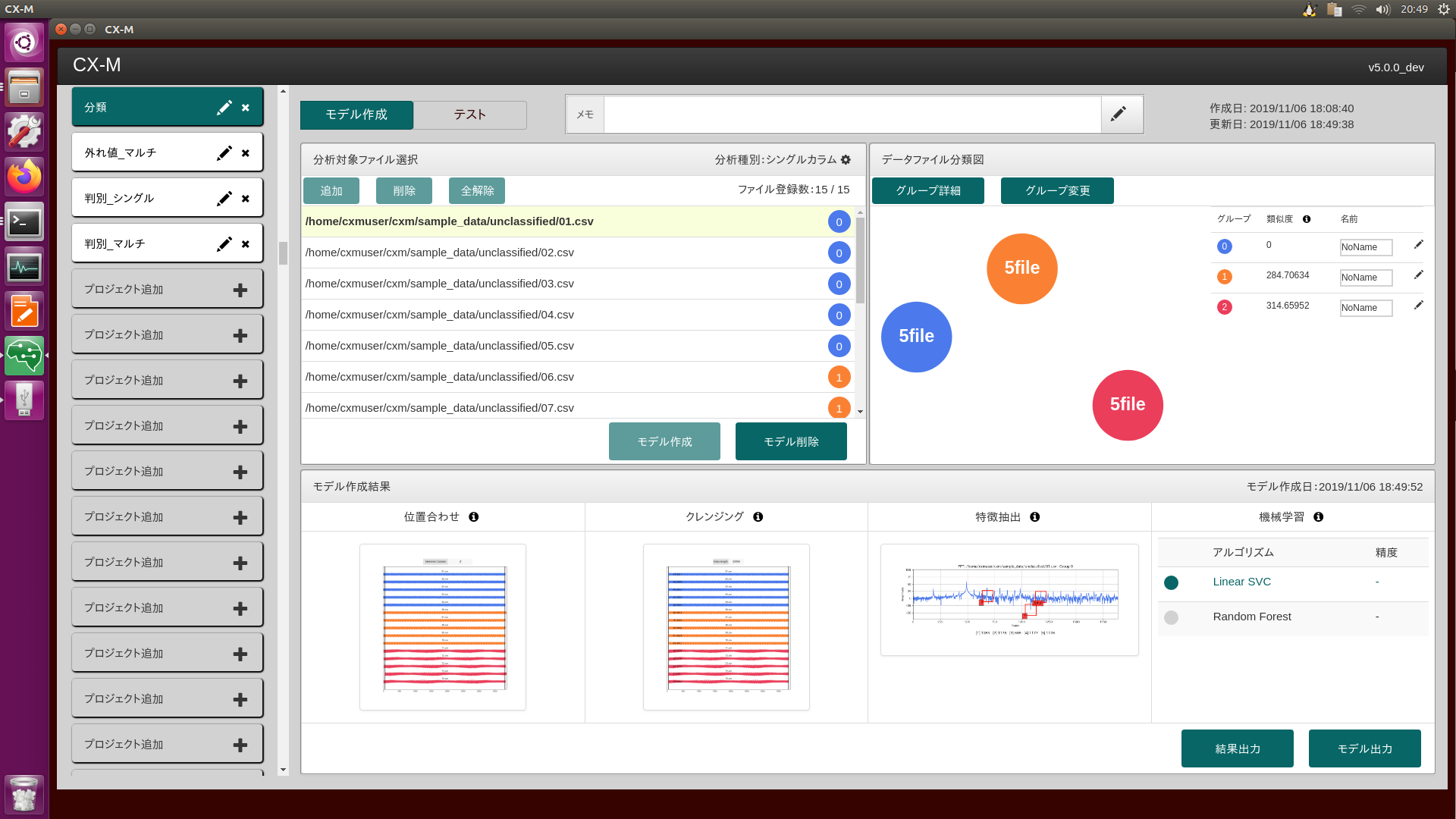
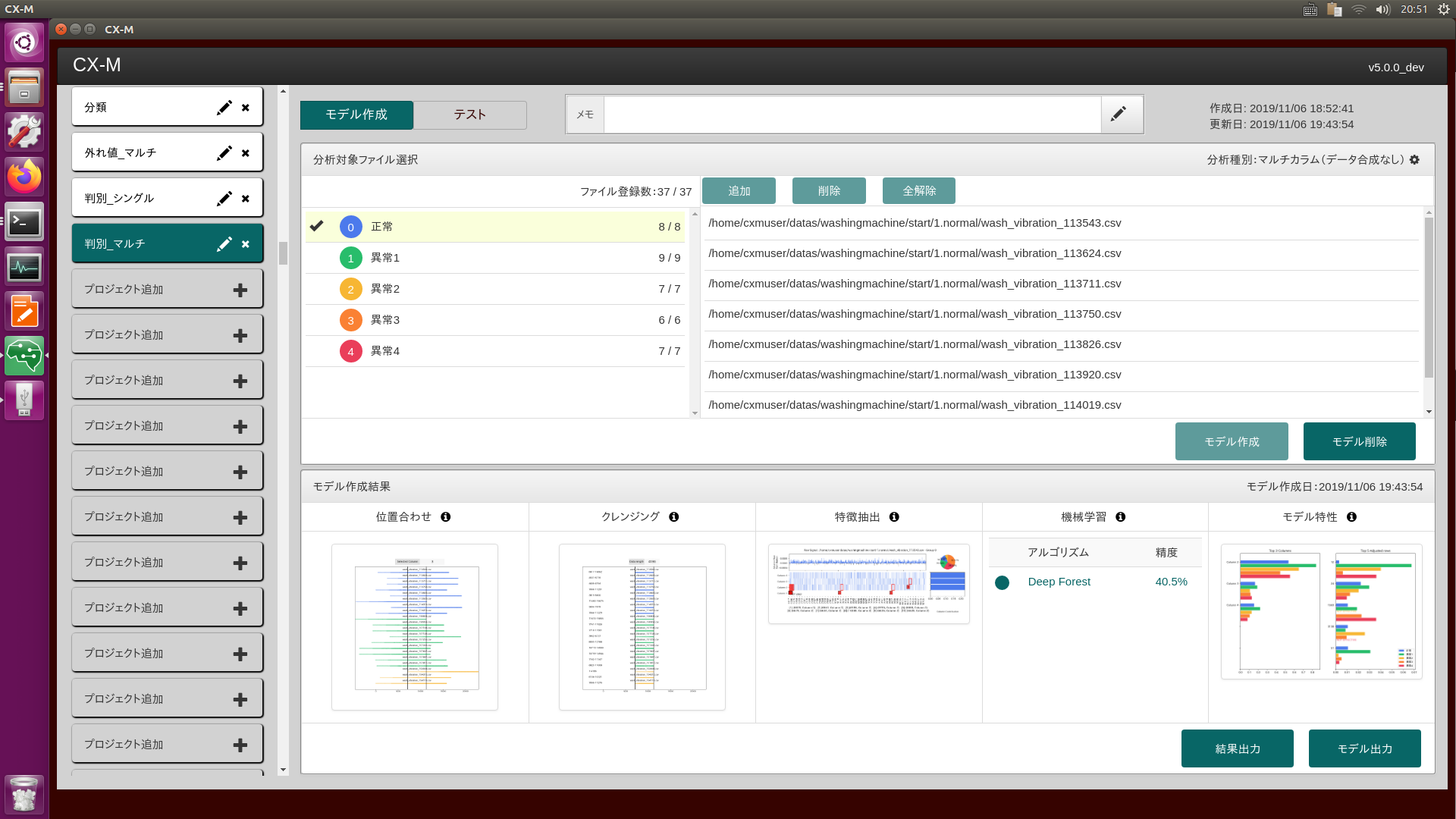
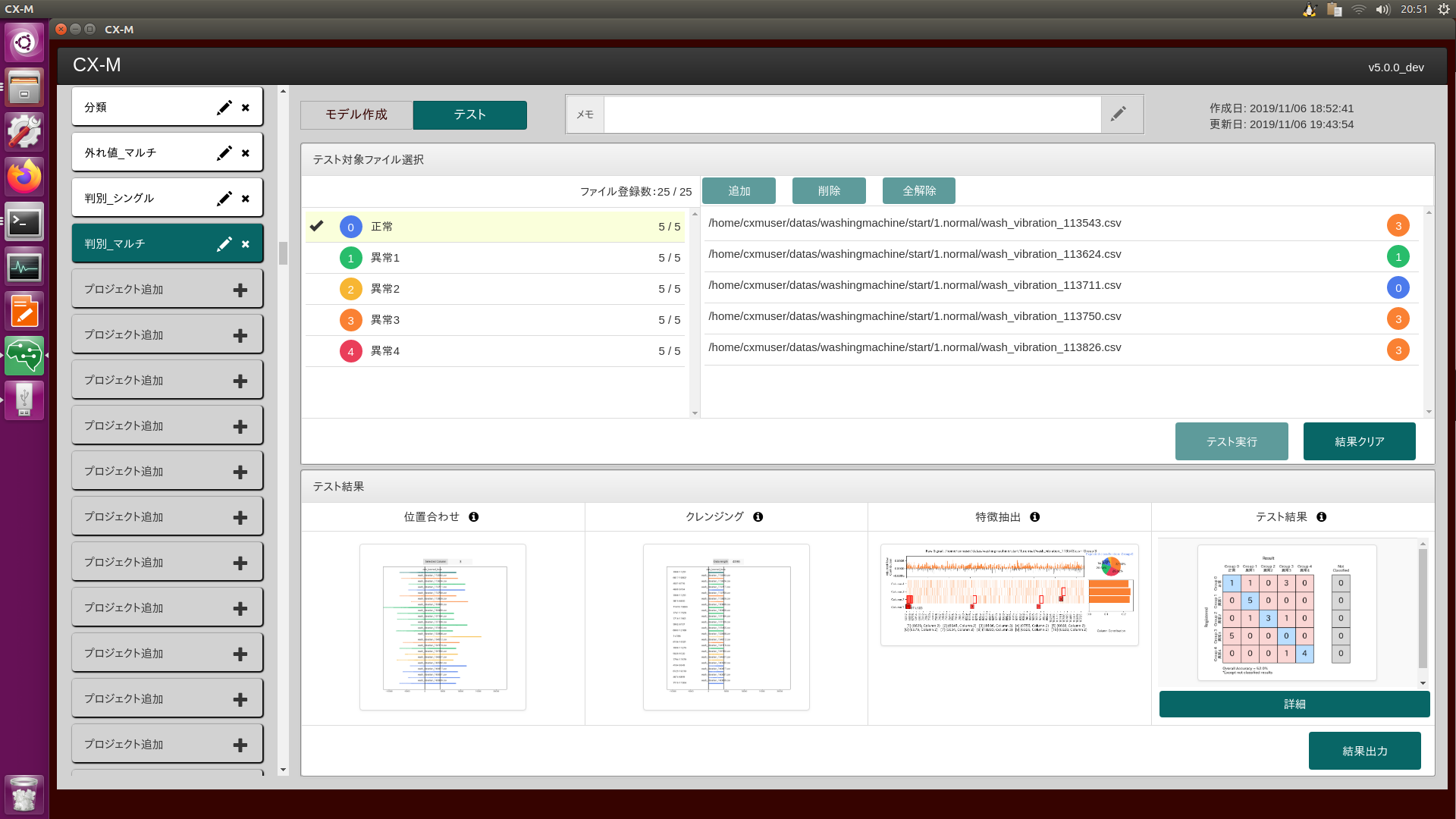
CX-Mは、製造現場の課題をデータ解析・分析で解決する時系列データ自動分析マシンです。1台で、異常検知・要因調査・状態診断のデータ分析を担い、予知保全(設備・工程異常検知)や品質改善(不良品の要因調査)をデータ活用の面でサポートします。従来データ分析の専門家(データサイエンティスト)が行っていた分析作業(データ前処理、特徴抽出、機械学習)およびプログラム開発作業(推論モデル作成)を完全に自動化しているため、モノづくり現場の技術者でもデータ分析を実践できます。

概要
AIが最短で結果を出す時系列データ自動分析マシン
製造現場の改善プロセスをDX化(デジタルトランスフォーメーション)するためには、モノづくりの知識や技術に加えて、ITやデータサイエンスといった新しい知識・技術が必要であり、想定以上に多くの時間とコストがかかっているのが現状です。CX-Mは、データ分析作業・推論モデル開発といった業務のDX化で必要となる作業を自動化し、1台で異常検知・要因調査・状態診断の3役の分析作業をサポートします。これによりデータ分析の知識がない利用者でも、現場課題である設備の予知保全、製造工程の異常検知、品質不良の要因調査をデジタルデータを活用し解決できます。

利点
CX-Mは、製造現場のデータ活用システムの実現に必要な3つの利点を持っています。
1つ目は、データ分析作業の自動化により専門家がいなくても、自社工場内で取り組みが進められることです。2つ目は、分析作業で作成した推論モデル(AI)をプログラム開発することなく、すぐに設備監視システムで利用できることです。最後は、こうした高度な機能をコストを抑えながら利用できる契約体系(サブスクリプション)です。
これにより、利用者は素早く利用を開始でき成果を出すことができます。
>>【特集記事】製造現場の改善プロセスをDX化する新手法とは
製造業の現場改善は、「生産ロスを顕在化」させることが非常に重要です。こうしたロスの要因を定量的にとらえ、設備の稼動に対する各ロスの影響度を把握することで、課題を明確にし改善を進めていきます。
特徴
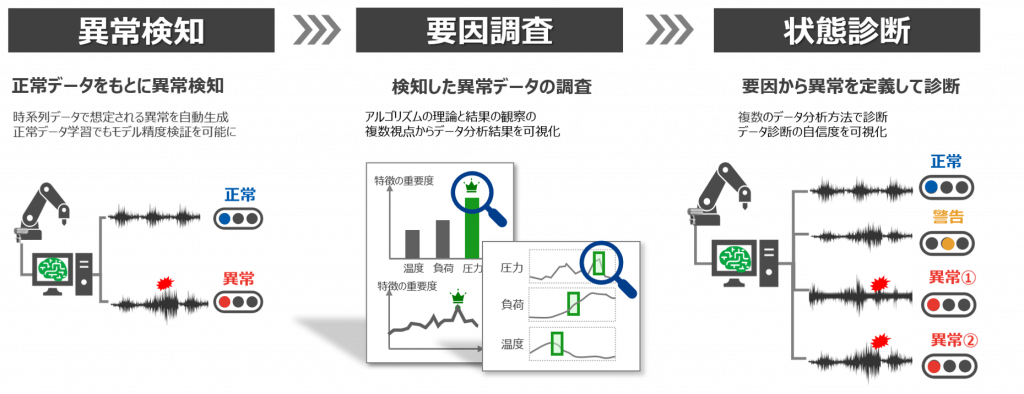
1. 1台で3役(異常検知・要因調査・状態診断)をこなす
CX-Mは異常検知・要因調査・状態診断の3つのテーマに対応したデータ分析機能があります。一つ目は、異常データが収集できていない現場でも、正常データのみから異常検知のモデルを作り出し設備監視を可能にする異常検知分析です。二つ目は、品質不良が発生した場合に、正常時と不良発生時のデータにどのような差があるのかを探索し要因を明らかにする要因調査分析です。そして3つ目が正常、異常などのデータから、正確に状態を判別するための状態診断分析です。これらの機能により、各現場の課題に合わせた活用が可能です。
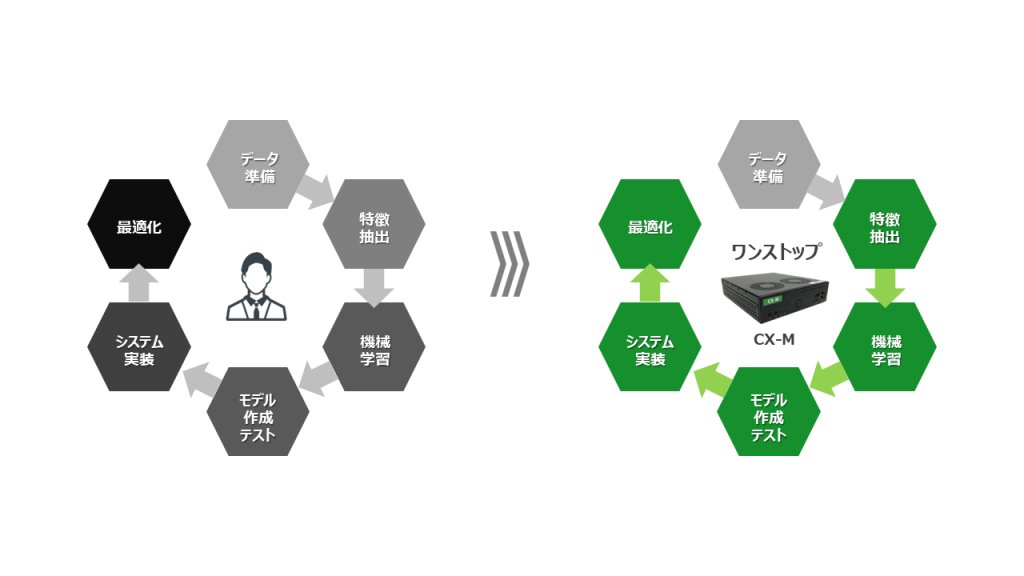
2. 最適な分析方法を探索し精度の高い推論モデルを自動生成
CX-Mは、時系列データの分析に必要な「位置合わせ」「特徴抽出」「機械学習」「モデル作成・テスト」「システム実装」「モデル最適化」等の一連の作業を自動で行い、どの組み合わせの処理が一番精度の良い結果が得られるかを試行錯誤し見つけ出します。そのため、従来人が仮設を立てながら繰り返し行ってきた探索的な分析作業を効率化し、素早く結果を得られるようになります。そして、多様なデータの特徴が捉えられるよう、特徴抽出には、トレンド、周波数(FFT)、周波数位相(Phase)、ヒストグラム(Histogram)スケーリング(Scaling)、時間周波数(Wavelet)などの多様な抽出技術を搭載し、機械学習(K-means、SVM(サポートベクターマシン)、RandomForest(ランダムフォレスト)、IsolationForest(アイソレーションフォレスト)等)との組み合わせで最良の結果を見つけます
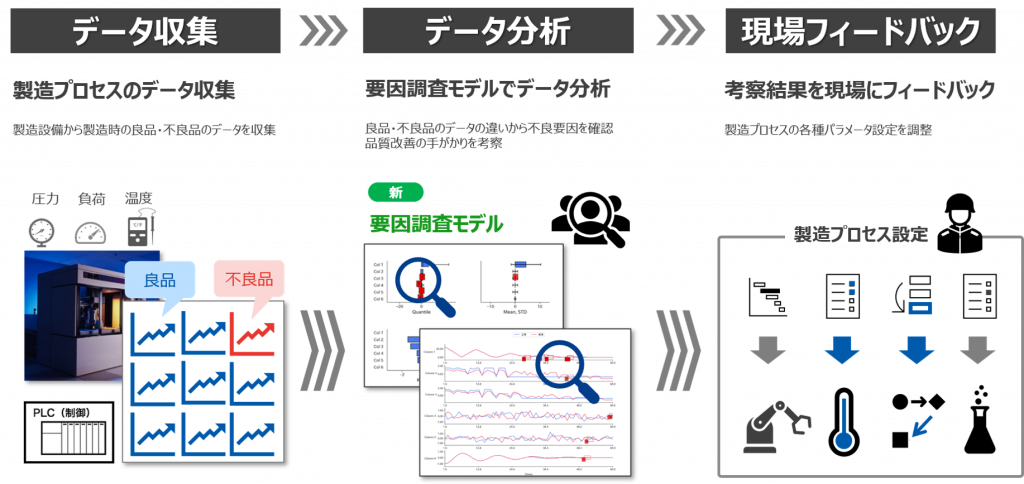
3. AIがデータ特徴を可視化 要因調査を可能に
AI・機械学習を使った分析では、作成した推論モデルがどのような特徴や論理で判断しているのかを定量的に可視化することができず、仮説による考察しかできませんでした。CX-Mは、推論モデルが判断するモデル特性を定量化するとともに、推論モデルが判断した根拠、自信度を可視化し、仮説ではなく事実に基づいた考察を可能にします。これにより製造現場では、技術者の経験に加えて、定量的な視点で判断された情報に基づき設備の異常検知や状態変化を察知し、予防保全から予知保全への転換や、品質改善のための設備設定を見直すことができます。
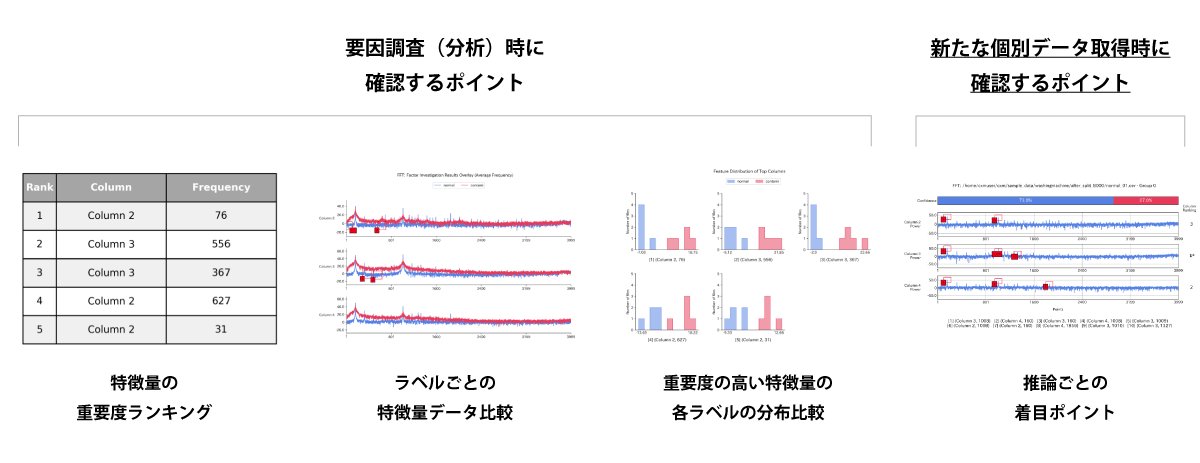
要因調査の業務イメージ
想定利用者比較
| CX-M | 一般的な分析ツール | |
|---|---|---|
| 工場作業者 | ◎マウス操作で分析可能 | △専門知識習得が必要 |
| 生産技術部門 | ◎マウス操作で分析可能 | △専門知識習得が必要 |
| IT技術者 | ◎マウス操作で分析可能 | △専門知識習得が必要 |
| 分析専門家 | ◎マウス操作で分析可能 (数値データの分析) |
◎さまざまなデータが扱える |
製品特性比較
| CX-M | 一般的な分析ツール | |
|---|---|---|
| 扱えるデータ | 数値データ特化 | 画像データ、数値データ、言語データ |
| 数値判別形式 | ファイル単位 | 行単位 (テーブル形式) |
| 操作性 | シンプル (マウス操作) |
複雑 (コマンド・キーボード) |
| 分析テーマ | 異常検知・要因調査・状態診断 | 数値予測・状態予測・要因調査 |
| 推論モデル開発 | 不要 (Edge利用できる推論モデル自動生成) |
必要 (Edge利用に別途プログラム開発) |
| 提供形態 | オンプレ | クラウド |
| 投資判断 | 事業部 | 会社 |

ユースケース
CX ユースケース1 加工機系(工作機械、プレス機、成型機、etc)
プレス機の金型状態診断
加工不良削減・ 交換タイミング最適化

工作機械の刃具状態監視
加工不良削減・ 部品在庫削減

成型機の製品不良監視
不良品削減、 品質影響の低減

切削加工機ボールねじ異常検知
品質影響の低減・チョコ停削減したい

グラインダー刃具 目詰まり監視
品質影響の低減・チョコ停削減したい

製造工程の品質影響調査
不良品削減、 品質影響の低減

CX ユースケース2 回転体系(モーター、ベアリング、ポンプ・・・)
ポンプ設備の異常検知
予知保全によるドカ停回避

ベアリングの外輪故障検知
保全業務の改善

減速機の状態診断
保全業務の改善

ロータリー式設備の状態診断
品質影響の低減 ・ チョコ停削減

軸受けの状態監視
保全業務の改善、メンテ計画の策定

製品検査の精度向上と安定化
動作検査の安定化、検査工数削減

CX ユースケース3 設備系(半導体製造設備、空調設備、etc)
生産設備の異常監視
保全業務の改善・品質安定化

半導体製造装置の状態監視
品質影響の低減・チョコ停削減したい

空調設備の予知保全
保全業務の改善

プロセス工程不良解析
半導体の良品・不良品の工程要因調査

成膜装置の品質調査
製品品質改善、品質不良の要因調査

製造品の検査改善
工程データで良否判定、検査工数削減

導入プロセス
CX-Mの検討、評価、導入、活用のフェーズに合わせたサポートサービスをご提供します。
【CX-M 評価・導入・活用のプロセス】



製品仕様
CX-Mハードウェアスペック

| 項目 | CX-M HW 第3世代 | |
|---|---|---|
| 筐体 | スリム型(ダブルファン付き) 165(幅)×190(奥行)×43(高)mm |
|
| 電源 | 120W ACアダプター | |
| 質量 | 1.32kg | |
| CPU | Intel® Core™ Ultra 7 265(20コア/20スレッド, 最大5.3GHz) | |
| メモリ | 64GB(DDR5 32GB SoDIMM ×2) | |
| ストレージ | M.2 SSD 256GB(Cドライブ)/ SATA SSD 1TB(Dドライブ) | |
| OS | Windows11 IoT Enterprise 2024 LTSC 64bit | |
| 温度 | 0~50℃ | |
| インターフェース | USB | (前面) USB3.2Gen2 ×2(TypeC×1含む)、USB2.0 ×2 (背面) USB3.2Gen2 ×2、USB3.2Gen1 ×2、USB4.0 ×1 |
| オーディオ | (前面) ヘッドホン出力 ×1、 マイク入力 ×1 | |
| 無線LAN | (背面) IEEE 802.11b/g/n/ac | |
| 有線LAN | (背面) ギガビットLAN ×2(2.5Gb/1GbE LAN) | |
| 映像端子 | (背面) HDMI ×1 、DisplayPort ×1 | |
| COMポート | (背面) RS232 ×1 、RS232/RS422/RS485 ×1 | |
紹介動画
CX-Mのご紹介動画
異常検知・要因調査・状態診断まで1台で3役をこなす時系列データ自動分析マシンCX-Mの製品概要のハイライトを動画でご紹介します。
予知保全の課題と対応
予知保全実現のための分析課題解決をご紹介
用語解説
時系列データとは
時系列データとは、時間的な変化を、連続的に観測して得られた値のデータです。データを時系列に並べることで、過去の様子を分析することも先の事象について予測することも可能になります。製造現場では、主に製造装置やセンサから出力されたデータが該当し、予知保全、品質改善、トレーサビリティなどのために利用されます。
データ前処理とは
データの前処理とは、得られたデータを何らかの機械学習アルゴリズムに入れる前に、そのデータに何かしら手を加えることをいいます。具体的には、分析に不要なデータの除去(列除去、工程除去、トリム処理)、データ分割(トリガ分割、スライド分割、固定長分割)、複数次元一度に扱う場合正規化(Standard スケール変換、MiniMax スケール変換、RobustScaler スケール変換)などがあります。また、生のデータのままではデータの内部構造や関係性を十分表していない場合が多くあります。そのため最大限にそのデータを活用するには、統計的処理を施す必要があります。
機械学習とは
機械学習とは、蓄積された大量のデータをコンピュータで学習し、分類や予測などのモデルを自動的に構築する技術です。機械学習には、「教師あり学習」、「教師無し学習」、「強化学習」などのカテゴリーがあり、それぞれのカテゴリには多数のアルゴリズムが存在します。(例:サポートベクターマシン(SVM)、ランダムフォレスト、ロジスティック回帰、クラスタリング)。機械学習の1つにニューラルネットワークが存在し、さらに、ニューラルネットワークのアルゴリズムの1つがディープラーニングです。
教師あり学習とは
教師あり学習は、人間があらかじめ付けた正解のラベルに基づき、機械が学習を行い、データセットに対する応答値の予測を行うモデルを構築する方法です。また、教師あり学習の問題は、結果を離散出力で予測する分類と、実際の値を予測する回帰という2つのグループに分けることができます。製造業では、設備状態が良い時のデータと、故障時のデータを用意し機械学習させてモデルを作成し、それを使って設備を監視するという利用形態(分類)や、生産計画の予測(回帰)などが考えられます。
教師なし学習とは
教師なし学習は、学習データに正解を与えない状態で学習させる手法です。教師あり学習と違い、膨大な教師データを学習せず、データが持つ構造・特徴を分析しグループ分けやデータの簡略化をします。主な方法として、データの特徴を抽出する次元圧縮(PCA)と、データを同じような集まりに分けるクラスタリングがあります。それ以外に「異常検知」あるいは「外れ値検知」を行うための、Isolation Forestというアルゴリズムもあります。
予防保全とは
予防保全とは、工場やプラントにある製造装置などの設備に対して、過去の経験を元に使用回数や時間を決めて、あらかじめ部品交換などを行うことにより、故障を未然に防ぐ方法です。また、「TBM(Time Based Maintenance)」と言われる稼働時間に応じて定期的に行われる手法が主流です。TBMは各設備でメンテナンス時期が決まっているため、保全計画を立てやすいという特徴があります。
予知保全とは
予知保全は、工場やプラントにある製造装置などの設備の状態をモニタリングし、不具合や異常の兆候を掴み、それを元に早めにメンテナンスを行い最適な稼働状態を保つ保全の手法です。同義で予兆保全とも言われます。予防保全のTBMに対して、予知保全はCBM(Condition Based Maintenance)と言われる、設備や機械の状態に応じて保全を行う手法です。センサやカメラ等で設備からデータを集めて状態を監視・把握し、しきい値を超えるなど異常の兆候がチェックして故障時期を予測し、稼働停止する前に対処します。設備が壊れて長時間の停止を強いられる「ドカ停」を未然に防げるのに加え、設備の状態を見ながら必要な時に必要な設備だけメンテナンスすれば良いので点検回数が減り、総じてダウンタイムを少なくできます。また副産物的に、保守・保全部門の人材不足や技能継承、メンテナンス用部材の在庫最適化と調達コスト削減などのメリットもあります。
位置合わせとは
位置合わせとは、取得した複数のデータ波形の位相(位置)を合わせる技術です。時系列データにて、周期的な信号における位置の違う(時刻が異なる)波が存在する、またはある特定の周期的な信号の場合に位相を少しずつ変化させていくと、波形の相関が高くなる点が存在します。そのため、データ取得時に取得開始のトリガーが無い場合は、取得開始のタイミングが毎回同じ条件に固定することが難しく、データごとに取得開始位置やデータ長が異なり、センシングしている情報と装置動作・異常特徴位置が合わないことが多いです。位相(位置)を合わせをすることにより、特徴を比較しやすくなります。
特徴抽出とは
特徴抽出とは、データが持つ特性を際立たせることであり、識別したい物体やデータから、分析にとってより有用な情報を取り出す操作です。主に、比較対象のグループごとに最もよく違いが出るように抽出する場合が多いです。特徴抽出の方法として、例えば、統計値を取得したり、フーリエ変換やウェーブレット変換などが使用されます。
スケーリングとは
スケーリングとは、与えられたデータを一定範囲に収めるよう変換することです。各データ列で取りえる値の範囲が大きいほど一単位当たりの変化量も大きくなります。このような列を複数次元一度に扱う場合は、変化量が大きい列の影響が強くなるため、一定のものさし(スケール)で計る必要があります。主な方法として、平均を0、分散を1にするStandard スケール変換、最小を0、最大を1とするMiniMax スケール変換があります。
フーリエ変換(FFT)とは
フーリエ変換とは、データの周波数特性に注目して、周波数成分の大きさや位相差に変換する方法です。波形データは様々な周波数を持つ単純な波の足し合わせで表現でき、フーリエ変換は波形データを周波数成分に分解します。波形データをフーリエ変換すると、周波数を横軸として対応する周波数の波が分解前の波形にどのくらい寄与しているかの強度を縦軸に表すパワースペクトルや、周波数を横軸として対応する位相差を縦軸に位相スペクトルなどの特徴を表示できます。また、フーリエ変換を離散的データに対して扱う場合、いくつかのアルゴリズムが存在しており、離散フーリエ変換(DFT)や高速フーリエ変換(FFT)などのアルゴリズムが存在します。
ウェーブレット(wavelet)変換とは
ウェーブレット変換とは、マザーウェーブレット呼ばれる基底関数のスケール(周波数)とシフト(時間的位置をずらし)によって、各時系列位置に含まれる周波数成分の大きさを時系列ごとに求める手法です。時間的変化の特徴と周波数成分の混在傾向を知るために用いられ、単位時間ごとに周波数にかかわる信号情報を同時に抽出することができます。
サポートベクターマシンとは
サポートベクターマシンとは、回帰・分類・外れ値検知などを行う方法の1つです。境界線に最も近いデータと境界線との距離を線形サポートベクトルに対するマージンと呼びますが、このマージンを最大化する境界線を引くための手法は機械学習の中でも主流の方法です。また、カーネル法を使用することで、円形のような曲線の境界線を引くことも可能です。線形分離になる高次元な空間を具体的に構築することは困難ですが、カーネル法ではカーネル関数と呼ばれる関数を使用することで、線形分離になる高次元な空間を具体的に構築することなく、高次元空間で学習した境界を使用できます。主なカーネル関数として、シグモイドカーネル、多項カーネル、RBFカーネルなどがあります。
エンベロープとは
エンペロープ(包絡線)とは、信号を絶対値化して、上部に接するような曲線を抽出します。さらに波形のピーク値間を補完することで、滑らかさをさらに追及することがあります。主にスパイク異常などのピーク検出等で使用されます。
決定木(ディシジョンツリー)とは
決定木は、学習データを条件分岐によって分割していくことで分類問題を解く手法であり、人間の思考プロセスに近い方法のため、結果が分かりやすいのが特徴です。決定木では、データの乱雑さを表す不純度が小さくなるようにデータを分割していきます。不純度を表す主な指標として、ジニ係数やエントロピーなどがあります。
ランダムフォレストとは
ランダムフォレストとは、複数の決定木を利用し、多数決をとる手法です。学習範囲が異なる複数の決定木を集めてアンサンブル学習を行うことで、決定木単体よりも高い汎化性能が得られ、回帰・分類のどちらでも使用可能です。アンサンブル学習とは、別々の決定木としてそれぞれ学習させた結果の多数決をとる学習方法で、バギングやブースティングなどがありますが、ランダムフォレストはバギングを使用しています。バギングは、ブートストラップサンプリングと呼ばれる、母集団の学習データの中から各決定木で使うデータをランダムに復元抽出することで、データセットに対して多様性をもたせる手法によって得られた学習データを用い、複数の決定木を作成しています。
アイソレーションフォレストとは
アイソレーションフォレストとは、「外れ値は正常値に比べて少ない分割数で分類できること」を概念として、複数の決定木の深さを指標に異常度を算出することで、外れの値を検知する方法です。ランダムに特徴量を抽出し、複数の決定木を作成します。決定木ごとに各特徴量が分割できるまでの階層の深さをスコア化し、スコアの平均値が小さい(ツリーが浅い)データは異常度が高いと判断します。
ディープフォレストとは
ディープフォレストとは、ツリー系アルゴリズム(例えばランダムフォレスト)をさらに多層化したアルゴリズムです。主に画像データやテーブルデータなどの分類に使用されます。ディープニューラルネットワークと比較し、ハイパーパラメータが少なく、学習データが小規模な場合でも良好な結果が得られることが特徴です。Multi-Grained Scanning と Cascade forest という大きく2つの処理に分かれ、前者は入力層にて抽象度が高い特徴、後者は出口層にて具象度が高い特徴を学習します。
特徴量重要度(Feature Importance)とは
特徴量重要度とは、ツリー系アルゴリズムで学習したモデルから、より説明性の高い特徴を定量化して表現したものです。ランダムフォレストなど決定木をベースとしたアルゴリズムにて、不純度と呼ばれるスコアの情報利得を最大化するようにルールが作られますが、ルール内の特徴の出現頻度とスコアの関係性から、各特徴量が分類に強い影響を与えているかの重要度を計算することができます。特徴量重要度は0~1の値を取りますが、値が大きいほどその特徴量が分類に与える影響が大きいことになります。
交差検証とは
交差検証とは、学習データと検証データとの分割パターンを複数構成して何度か検証を行い精度を評価する方法です。データ分割の偏りを避けるために、複数パターンで検証し、平均的な精度を求めます。データ分割には様々な方法がありますが、良く使用される方法に KFold、Stratified KFold や Leave One Group Out(LOGO)などがあります。例えば、KfoldではデータセットをK個のグループ(フォールド)に等しく分割します。その中から1グループを検証データ、残りのグループを学習データとしてモデルを作成します。これをK回グループ間で検証データをローテーションし、K個のモデルを作成します。最後にK個のモデルの精度の平均値をとることで最終的な精度を求めます。
クラスタリングとは
クラスタリングとは、教師なし学習の代表的なタスクであり、データの中から特徴の似ているデータをグルーブとしてまとめます。どのようなカテゴリーのデータが何種類あるかを確認する際に利用されます。予知保全の分野においては、異常データが少ないため、大多数のデータが存在したグループのデータを「正常データ」と定義する際に使用されます。
クロスコンパイルとは
クロスコンパイルとは、開発に使用している機種のCPUアーキテクチャーやOSとは異なる環境向けに実行可能なアプリケーションを生成することです。これにより、Windows および LinuxのOS もしくは複数の種類のCPU環境下(ARM、i386、AMD64など)でもAIを実行することが可能です。
説明可能なAIとは
説明可能なAI(人工知能)とは、機械学習のアルゴリズムによって作成される一般的にはブラックボックスな結果を人間が理解できるようにする一連のプロセスと方法です。AI対応システムがどのように特定の結果を導き出したかを理解することで、結果が妥当であることを確認できます。それを実現できるものとして、LIME、SP-LIMEなどがあります。
クラス分類(classification)とは
クラス分類とは、教師として定義したクラスに、データを分類する手段のことです。分類する数によって、2クラス分類と多クラス分類に分かれます。2クラス分類(判別)は、与えられたデータが正常や異常などの2種類のグループのどちらに属するのか判別するための方法です。一方、多クラス分類は、状態数と状態ごとの分布や傾向を定義できている場合、各状態グループごとの特徴を捉えて、どのグループに当てはまるのかの基準(線、面、ルール)を学習し、学習した基準に基づいて新たに観測したデータの状態を判別するための方法です。単純ベイズ分類器など確率統計に基づく分類、パーセプトロンやサポートベクターマシンなどの距離に基づく分類、ルールに基づく分類など様々な分類するための基準のアルゴリズムが存在します。
異常検知(anomaly detection)とは
異常検知とは、一般的には広い意味で異常の発見いうことですが、当社では取得したデータを監視し、一定の観点において、「いつも通りの状態とは異なる」状態を検知する装置状態監視として使用しています。過去に正常稼働したデータから振幅の範囲が大きく外れた場合(外れ値検知)、定期的に繰り返す正常稼働のデータパターンが異なる場合(異常部位検知)、正常に稼働した状態から異なる状態に変化するポイントがある場合(変化点検知)などを捉える方法があります。正常データからの変化を検知するため、異常データがない場合でも装置の状態監視が行えます。
外れ値検知(outlier detection)とは
外れ値検知は異常検知の代表的な方法で、定常状態の分布から大きく離れた位置にデータがあることを見つける方法です。
関連製品・サービス


関連記事









導入事例
100μsの高速AEモニタリング環境でCX-Mによる良否判別を実現、品質確保に活用!
導入事例
振動データの整理・分析・比較作業を大幅に改善
導入事例
製造現場の品質管理を自動化!インラインの品質判定で不良流出0へ
導入事例
製造現場の「データ収集と分析」の見えない壁をシーケンサで突破!










関連記事
時系列データ自動分析マシン 製品外観