- HOME
- 【工場DX】予知保全に最適なAIを見極める データ検証で徹底比較した結果とは
生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極める
データ検証で徹底比較した結果とは

現在、様々な分野で活用が進んでいるAI。製造業の現場では、設備の状態監視の強化として予知保全を実現するためにAIの活用が検討されています。AIには、従来の機械学習と深層学習(ディープラーニング)があります。「画像データでは、ディープラーニングの活用例が多くみられるが、センサーデータやログデータのような時系列データでもディープラーニングが最良な選択肢なのか?」という疑問をよく耳にします。予知保全への利用は従来の機械学習とディープラーニングのどちらを選択するのがよいのでしょうか。
そんな疑問に対して前回の第1弾では、アルゴリズム選択の勘所をお伝えしました。第2弾では、実際に予知保全のデータを用いて、従来の機械学習とディープラーニングのアルゴリズムのパフォーマンスを比較検証します。
目次
『予知保全への第一歩!データ分析入門ガイドブック』

連載記事<予知保全に最適なAIとは? >
第1弾:「アルゴリズム選択の勘所」
第2弾:「データ検証による精度と処理時間の比較」
第3弾:「AIの実導入における課題とソリューション」
前回の第1弾では、予知保全の領域で使われるデータの特徴と、従来の機械学習とディープラーニングの違い、予知保全に適用する際のポイントとして、2つのコストバランスを考慮することが重要であることをお伝えしました。具体的には、「人が作業することによる工数」と、「機械学習そのものにかかるコスト」です。
今回の第2弾では、主に「機械学習そのものにかかるコスト」について取り上げます。
実際に予知保全で使われる時系列データを想定し、従来の機械学習とディープラーニングの学習アルゴリズムの違いを「精度(正解率)」と「処理時間(学習と推論)」の観点で比較検証します。

製造現場での予知保全の例として、ある工場の例を考えてみましょう。工場には様々な装置がありますが、装置を円滑に動作させる際にはベアリング(※1)という部品が欠かせません。ベアリングは、切削加工機やロボットアーム、プレス機等、製造現場の様々な装置に使用されています。
※1 ベアリングは装置回転時の摩擦をできるだけ小さくします。摩擦を減らすことで機械の稼働効率を高める、機械の寿命を長くする、焼き付けを防ぐことで機械の故障をなくす等の役割があります。このベアリングは、装置の経年使用によって潤滑状態が悪くなる、錆が発生する等の劣化が起こり、故障するという事象が発生します。
【切削加工機】

【ロボットアーム】
【NC工作機械】
今回はベアリングの故障検知をテーマとして、2つのサンプルデータを使って検証を行います。
これらのデータは、いずれもベアリングの外輪に異常が発生する耐久試験のデータです。それぞれの装置の動作状態およびデータ取得環境は以下の通りです。
-
サンプルデータ1
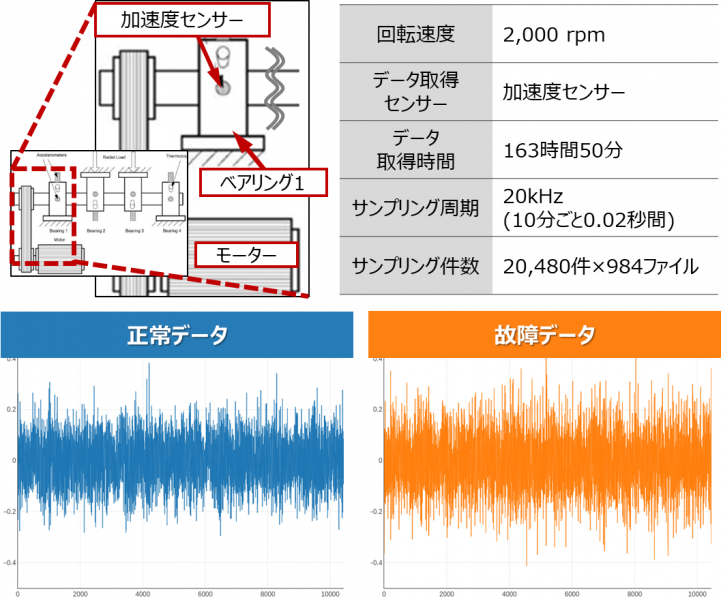
この装置は、4つのベアリングがシャフトに取り付けられており、バネによって約2700kgの荷重がかかる仕組みです。設計想定以上の回転を続けることで(1億回転以上)このうち1つのベアリングの外輪に摩耗が発生し、故障するデータです。
-
サンプルデータ2
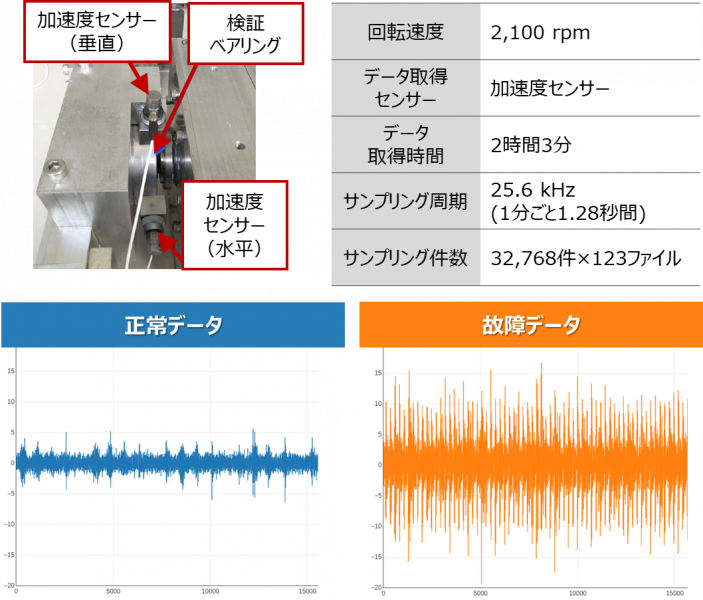
この装置は、1つのテスト用ベアリングが2つのサポート用ベアリングと共にシャフトに取り付けられており、油圧によって約1200kgの荷重がかかる仕組みです。水平垂直方向に取り付けた2つ加速度センサーで、故障によって通常稼働時の10倍の振幅となるまで、データを取得しています。
2つのサンプルデータの正常時と故障時の一部データをグラフで可視化すると一定の振幅で振動しているデータであることがわかります。
サンプルデータ2では、故障時は明らかに波形の振幅が大きく振動が大きいことがわかりますが、サンプルデータ1は人間の目には判り難く、異常を捉えにくいデータといえます。

この2つのデータの状態の違いを従来の機械学習とディープラーニングのアルゴリズムを使って学習し、「精度(正解率)」と「処理時間(学習と推論)」の違いを見てみましょう。
今回は、従来の機械学習とディープラーニングで、それぞれ時系列データに適した以下のアルゴリズムを選択しました。これらのアルゴリズムはいずれも「正常」のデータのみを学習し、正常かそうでないかを判断するアルゴリズムです。「異常」のデータは、テストデータとして検証には使用しますが、学習には使用しません。
【今回検証に用いるアルゴリズム】
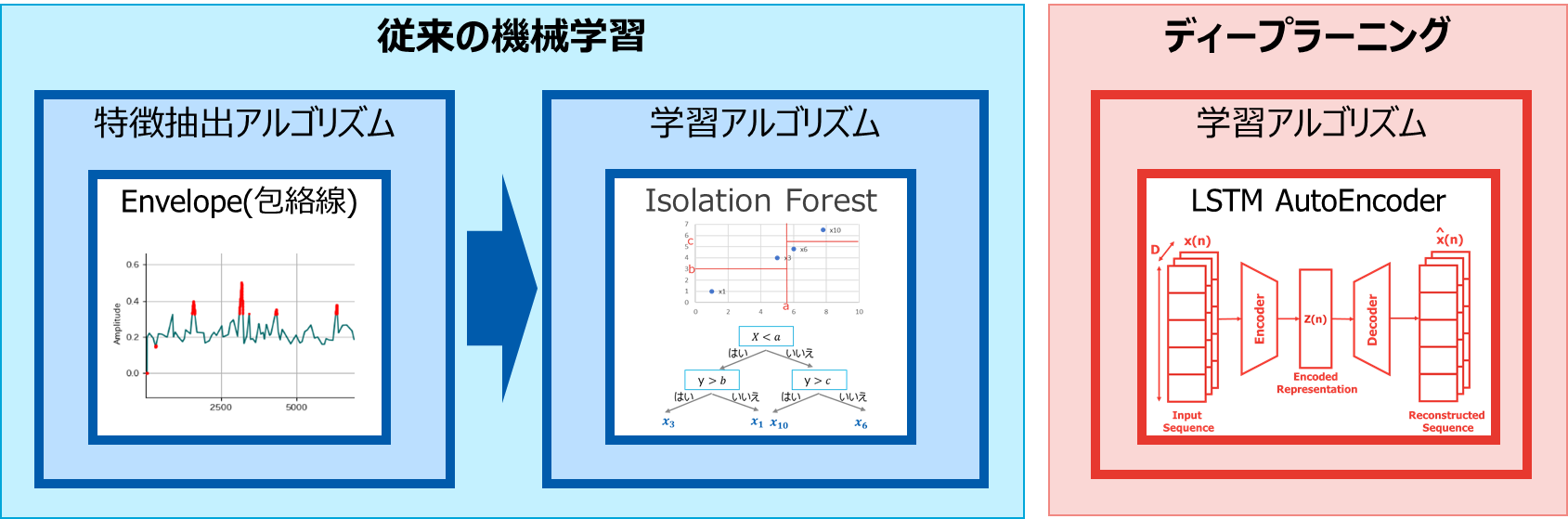
【従来の機械学習とディープラーニングの違い】
・従来の機械学習

・ディープラーニング

前回の第1弾でもお伝えしたように、従来の機械学習では、機械学習の処理の前に、データの特徴を捉える「特徴抽出」の処理が必要になります。このため、特徴抽出のアルゴリズムも併せて選択します。
ディープラーニングは、予知保全で扱う時系列データに適したアルゴリズムがまだ少ないですが、現状高い精度が見込まれる「LSTM AutoEncoder」を使って検証を行います。また、ディープラーニングは従来の機械学習と異なり、機械学習の処理の中で「特徴抽出」を行うことができる特性がありますので、特徴抽出は行いません。
また、データ検証に用いたマシンのスペックは以下になります。
| CPU | Intel(R) Core(TM) i7-8700 CPU @ 3.20GHz |
|---|---|
| メモリ | 32GB |
| OS | Ubuntu 16.04.6 LTS x86(64bit) |

従来の機械学習とディープラーニングの精度(正解率)が、学習するデータ件数(ファイル数)によってどのような違いがでるのかを比較してみましょう。「精度」を測るには、主に「正解率」「適合率」「再現率」の視点を用いることができますが、ここでは「正解率」を取り上げます。
【「正解率」「適合率」「再現率」とは】
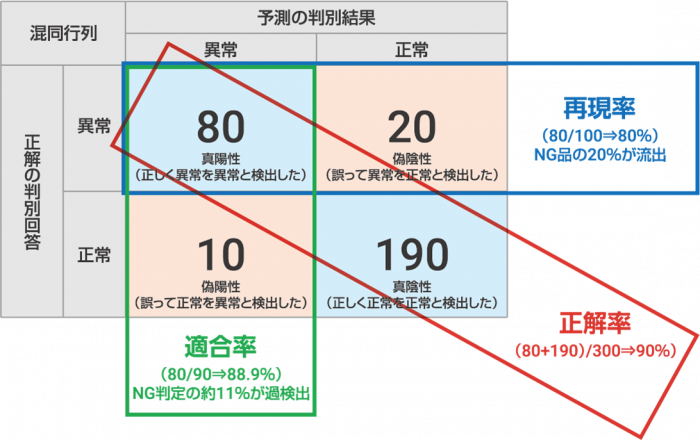

それでは精度(正解率)を比較した結果を見てみましょう。
【従来の機械学習とディープラーニングの精度(正解率)比較】
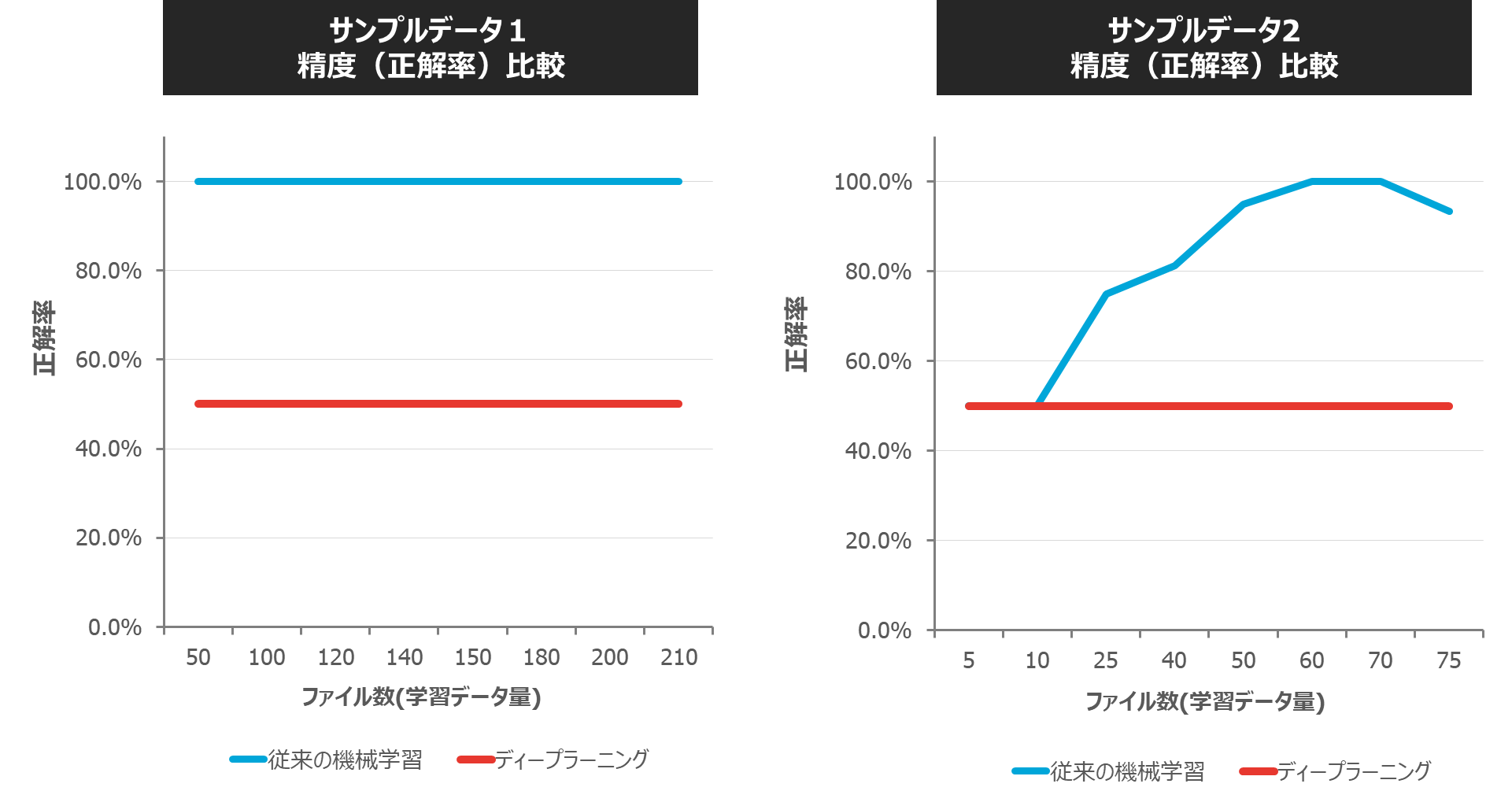
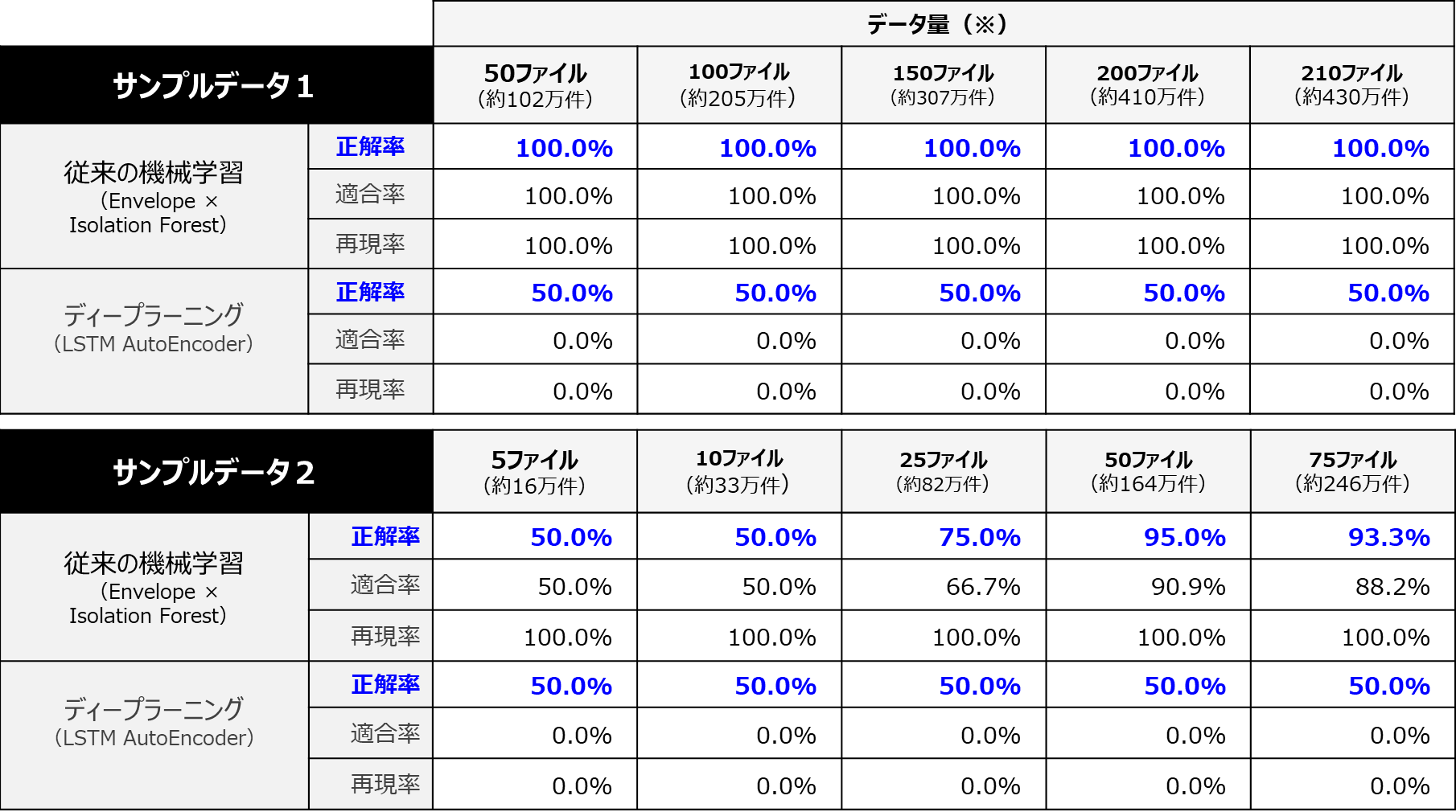
※データ量は、学習データとテストデータの合計のファイル数(件数)です。学習データとテストデータは、正常データファイルを6:4の割合で分けています。
従来の機械学習は、データ件数が増えるに従って、学習の精度が上がっていることを確認できましたが、今回ディープラーニングでは、データの件数を増やしても全く精度が上がらない結果となってしまいました。

あわせて、処理時間(学習と推論)の視点でも比較してみましょう。
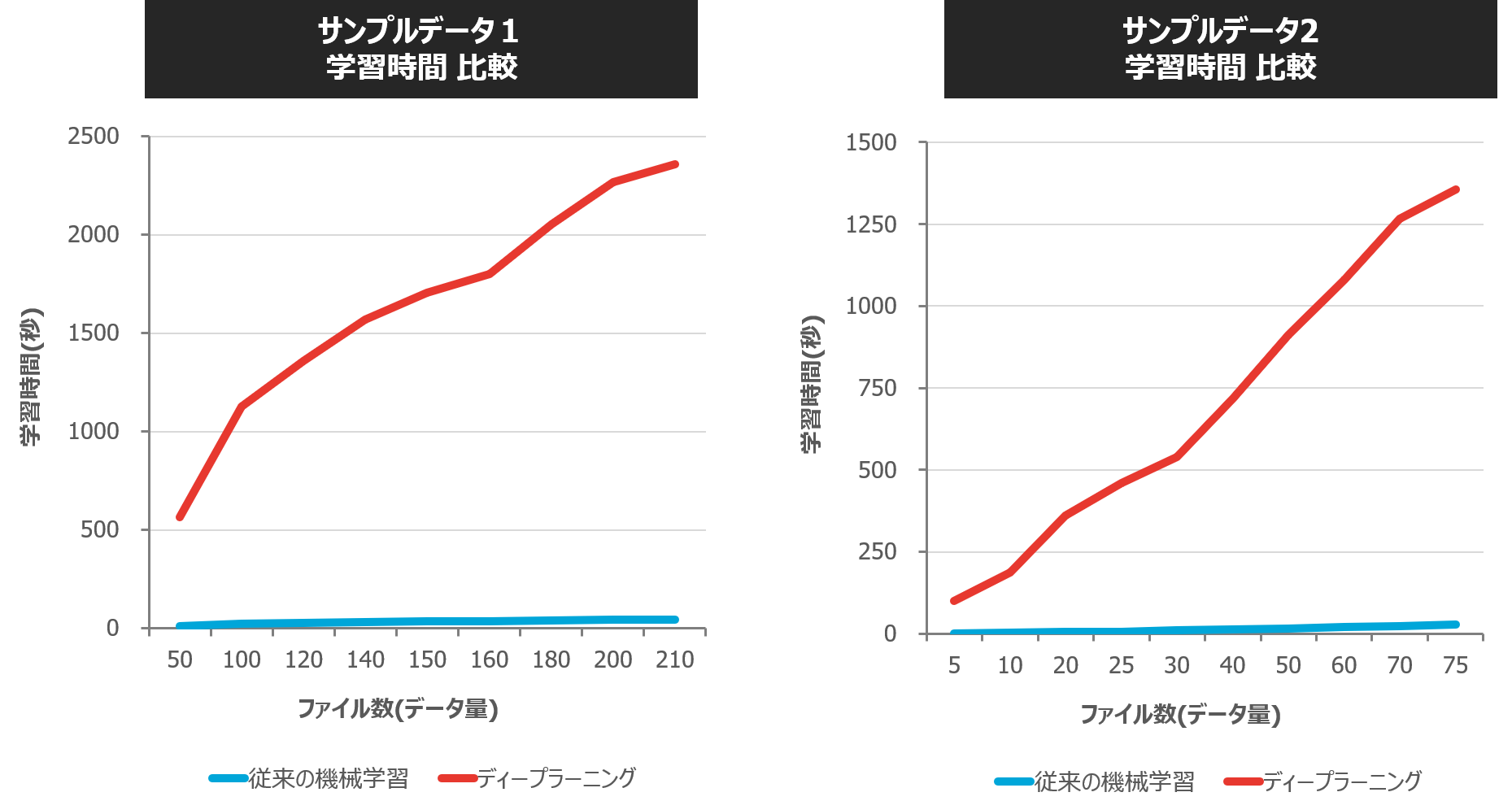
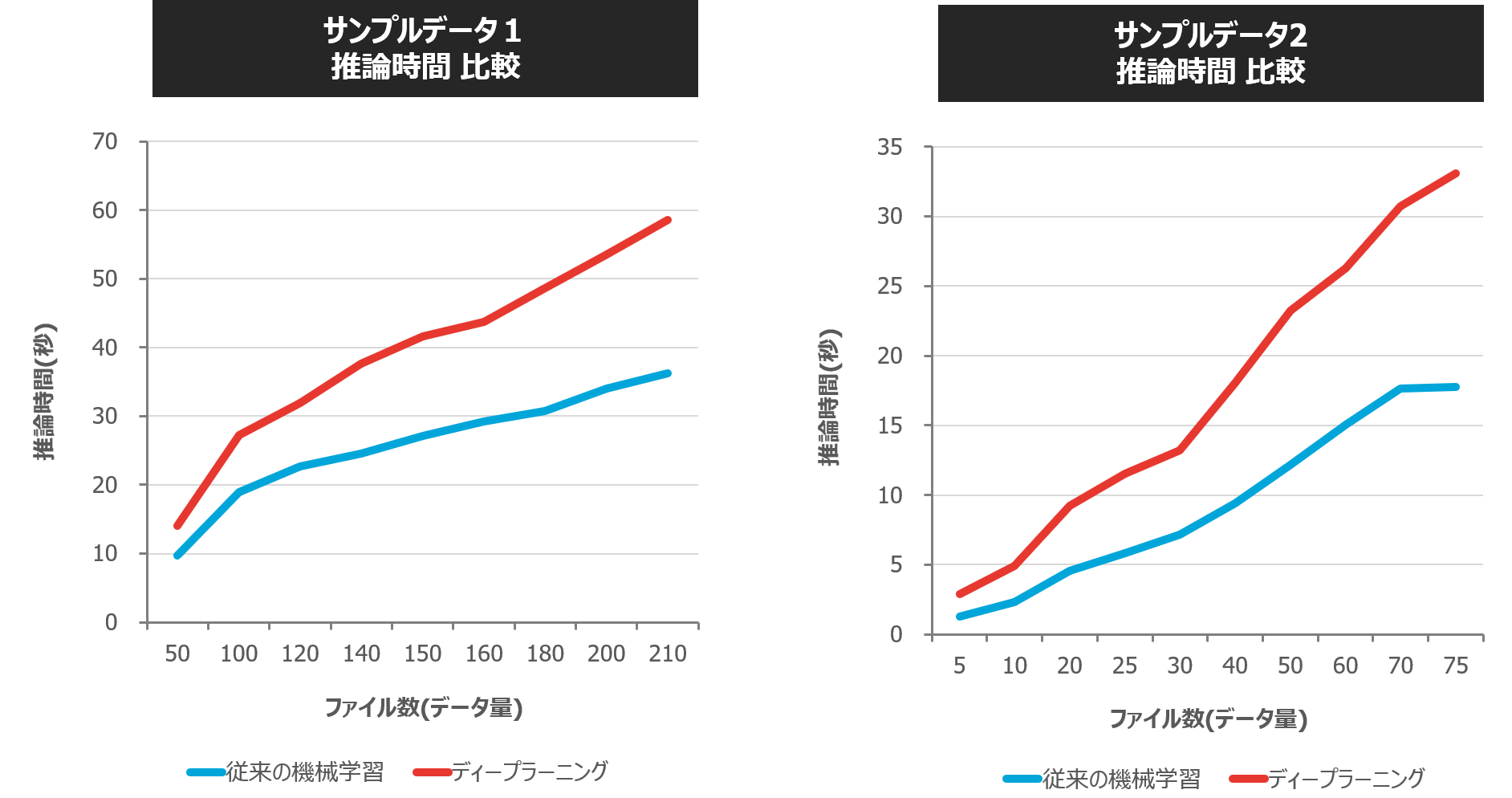
【従来の機械学習とディープラーニングの処理時間(学習と推論)比較】

・学習時間 ・・・ 学習にかかる処理時間(学習により学習モデルが作成されます)
・推論時間 ・・・ 学習モデルがテストデータの正常と異常の判定にかかる処理時間
従来の機械学習に比べてディープラーニングでは学習時間が数十倍以上、データ量によっては数百倍の処理時間がかかっていることが分かります。また、従来の機械学習ではデータ件数が増加しても処理時間は大きく増加しませんが、ディープラーニングでは、データ件数の増加に比して処理時間がかかっています。推論時間についても、学習時間ほどではないものの、従来の機械学習の方がやや処理速度が速い結果となりました。

なぜ、高い精度が見込めると言われているディープラーニングで精度が低くなってしまったのでしょうか?考察の結果、今回選択した「LSTM AutoEncoder」のアルゴリズムが、今回のテーマのデータの特徴を捉えることができていないのではないか?という仮説を立てました。
この仮説を検証するために、ディープラーニングでは通常行わない「特徴抽出」を行った上で、ディープラーニングのアルゴリズム「LSTM AutoEncoder」で再度検証してみます。特徴抽出のアルゴリズムは従来の機械学習と同様に「Envelope(包絡線)」を用います。
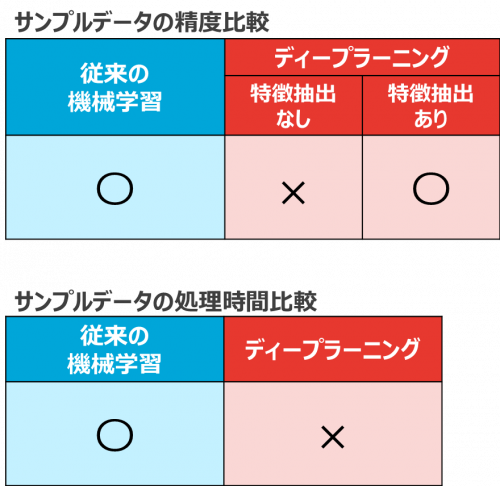
【従来の機械学習とディープラーニング+特徴抽出の精度(正解率)比較】
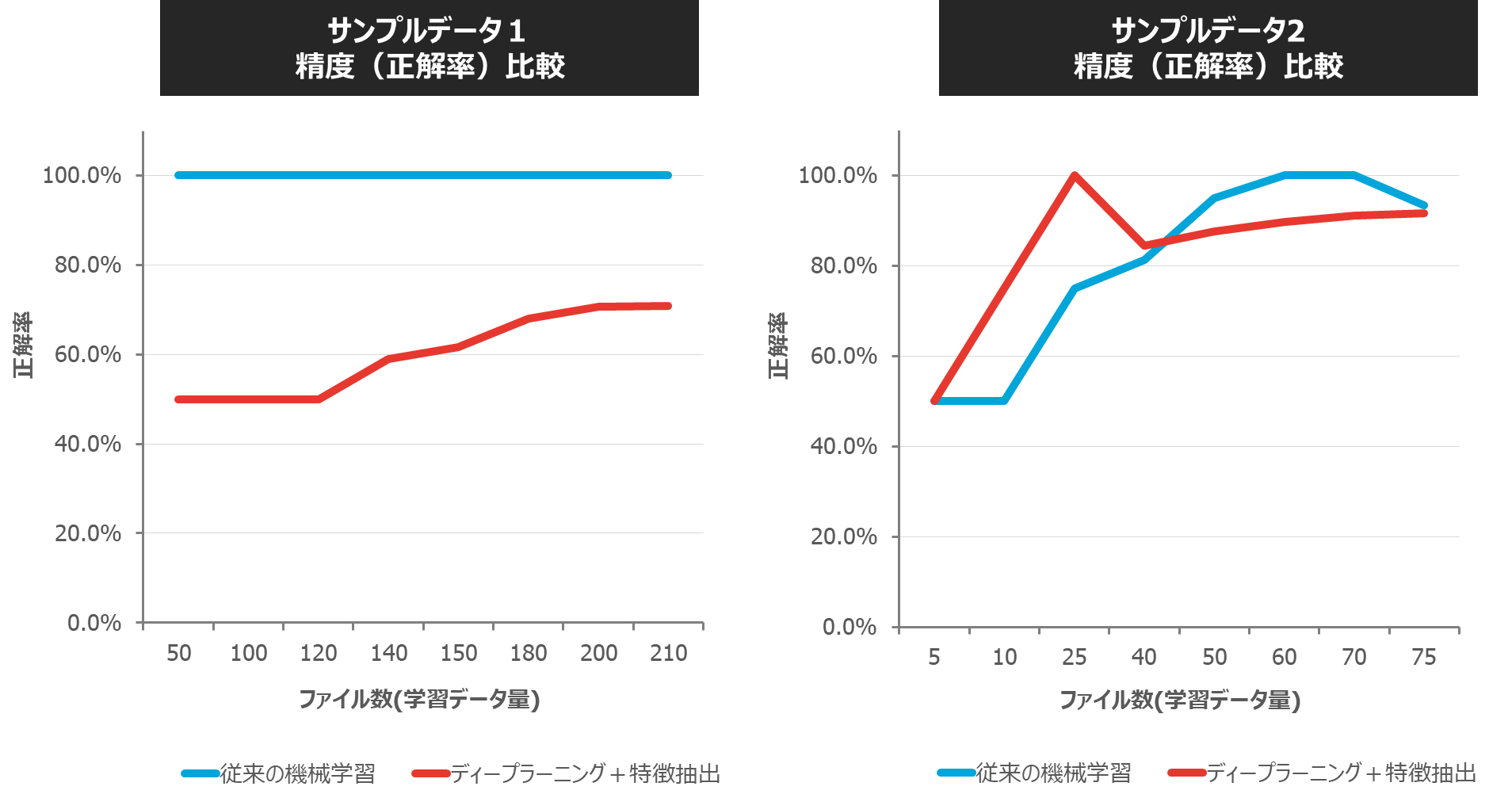
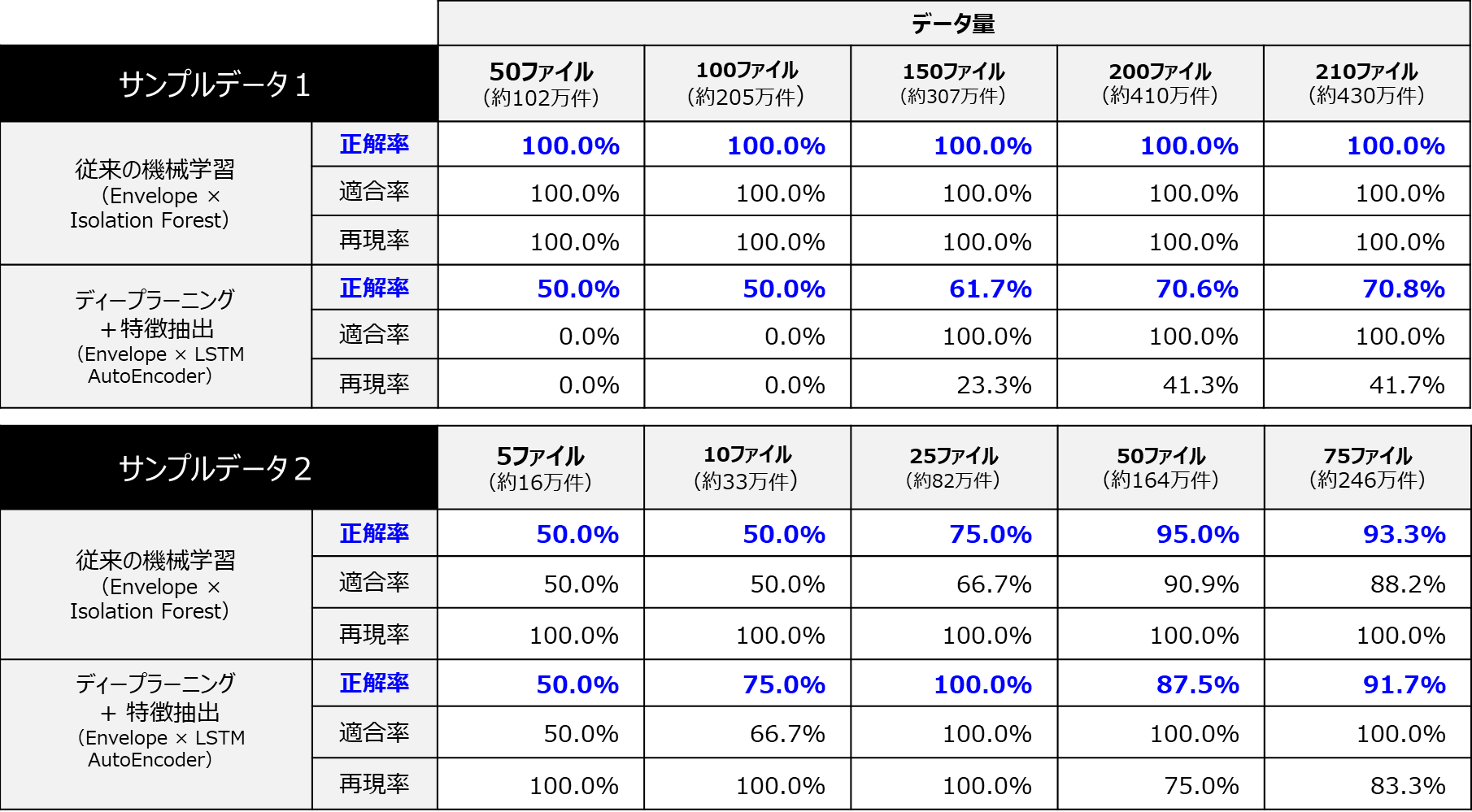
サンプルデータ1では、従来の機械学習より下回るものの、ディープラーニングのみの場合と比較すると精度の向上がみられました。サンプルデータ2では、機械学習とほぼ同程度の精度、データ量によっては従来の機械学習をやや上回る精度が得られました。
この結果から、ディープラーニングにおいても、「特徴抽出」の手法は有効であり、また、特徴抽出なしでは、精度を見込めない時系列データのケースがあることが確認できました。

以上の一連のデータ検証の結果、「精度(正解率)」の観点では、従来の機械学習、ディープラーニング共に「特徴抽出」と「機械学習」のアルゴリズムを適切に選択することで、高精度の学習結果が得られることが分かりました。
また、「処理時間」の観点では、従来の機械学習に比べて、ディープラーニングはデータ量に比例して非常に処理時間がかかることが分かりました。
これらの考察から、従来の機械学習でも十分に高精度で処理速度の速い学習結果が得られると考えられます。
しかし、今回のデータ検証の視点には含めていませんが、「特徴抽出」と「機械学習」の最適なアルゴリズムを選択するには、「人が作業することによる工数」がかかります。今回の検証では、過去のノウハウを元に時系列データに適していると考えられる特徴抽出や機械学習のアルゴリズムを選びましたが、実際には多種多様なアルゴリズムの中から最適なものを選択するために、トライ&エラーを繰り返しながら学習の精度を上げていく必要があります。実際の製造現場においては、そのような工数をかけることは難しいことが多いのが現状ではないでしょうか。
それでは、製造現場でこうした「人が作業することによる工数」をかけずに、予知保全領域のデータで精度の高い学習ができるような解決策は無いのでしょうか?次回の第3弾では、この課題に対してTEDのソリューションをお伝えします。お楽しみに。
『予知保全への第一歩!データ分析入門ガイドブック』
ディープラーニングとは
ディープラーニング(Deep Learning)とは、機械が自動的にデータから特徴を抽出してくれる技術です。ディープラーニングには、複数のアルゴリズム(DNN, CNN, RNN)があり、目的にあったものを選定する必要があります。
・DNN(ディープニューラルネットワーク)
人間や動物の脳神経回路をモデルとしたアルゴリズムを多層構造化したものです。
・CNN(畳み込みニューラルネットワーク)
DNNを2次元データに対応させたもの。画像に対して高いパターン認識能力があります。
・RNN(再帰型ニューラルネットワーク)
DNNを横に繋いで時間変化する、連続的なデータに対応させたものです。
学習モデルとは
学習モデルとは「機械学習モデル」を指し、人間が経験を通して学習し判断することをコンピュータで実現するものです。学習モデルは、アルゴリズムを使いサンプルデータを繰り返し解析し規則(ルール)を発見することで作成されます。サンプルデータの量と質が機械学習モデルの精度の鍵となります。「入力=>モデル=>出力」というプロセスで動作し、データを入力しモデルが評価・判定を行い結果を出力します。

