- HOME
- 【工場DX】予知保全に最適なAIを見極める AI導入の課題と解決方法とは
生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極める
AI導入の課題と解決方法とは

現在、様々な分野で活用が進んでいるAI。製造業の現場では、設備の状態監視の強化として予知保全を実現するためにAIの活用が検討されています。
AIには、従来の機械学習と深層学習(ディープラーニング)があります。「画像データでは、ディープラーニングの活用例が多くみられるが、センサーデータやログデータのような時系列データでもディープラーニングが最良な選択肢なのか?」という疑問をよく耳にします。
そんな疑問に対して、これまでアルゴリズム選択の勘所と実際のデータ検証についてお伝えしてきました。第3弾では、実際に製造業の現場でAI導入を進める上での課題とTEDのソリューションをお伝えします。

連載記事<予知保全に最適なAIとは? >
第1弾:「アルゴリズム選択の勘所」
第2弾:「データ検証による精度と処理時間の比較」
第3弾:「AIの実導入における課題とソリューション」
これまでの第1弾では、従来の機械学習とディープラーニングの違いをご紹介するとともに、AIを予知保全に適用する際に必要な「人による作業工数」と「機械学習そのものにかかるコスト」のコストバランスの重要性をお伝えしました。
第2弾では、「機械学習そのものにかかるコスト」にフォーカスし、実際の予知保全のデータを想定して、従来の機械学習とディープラーニングの「精度」と「処理速度」を比較検証しました。
その結果、従来の機械学習でも十分な精度と処理速度を発揮できること、従来の機械学習とディープラーニング共に「特徴抽出」と「機械学習」のアルゴリズムを適切に選択することがポイントであることが分かりました。

これらを踏まえて、製造業の現場でAIを導入しようとすると、何が起こるかを考えてみましょう。
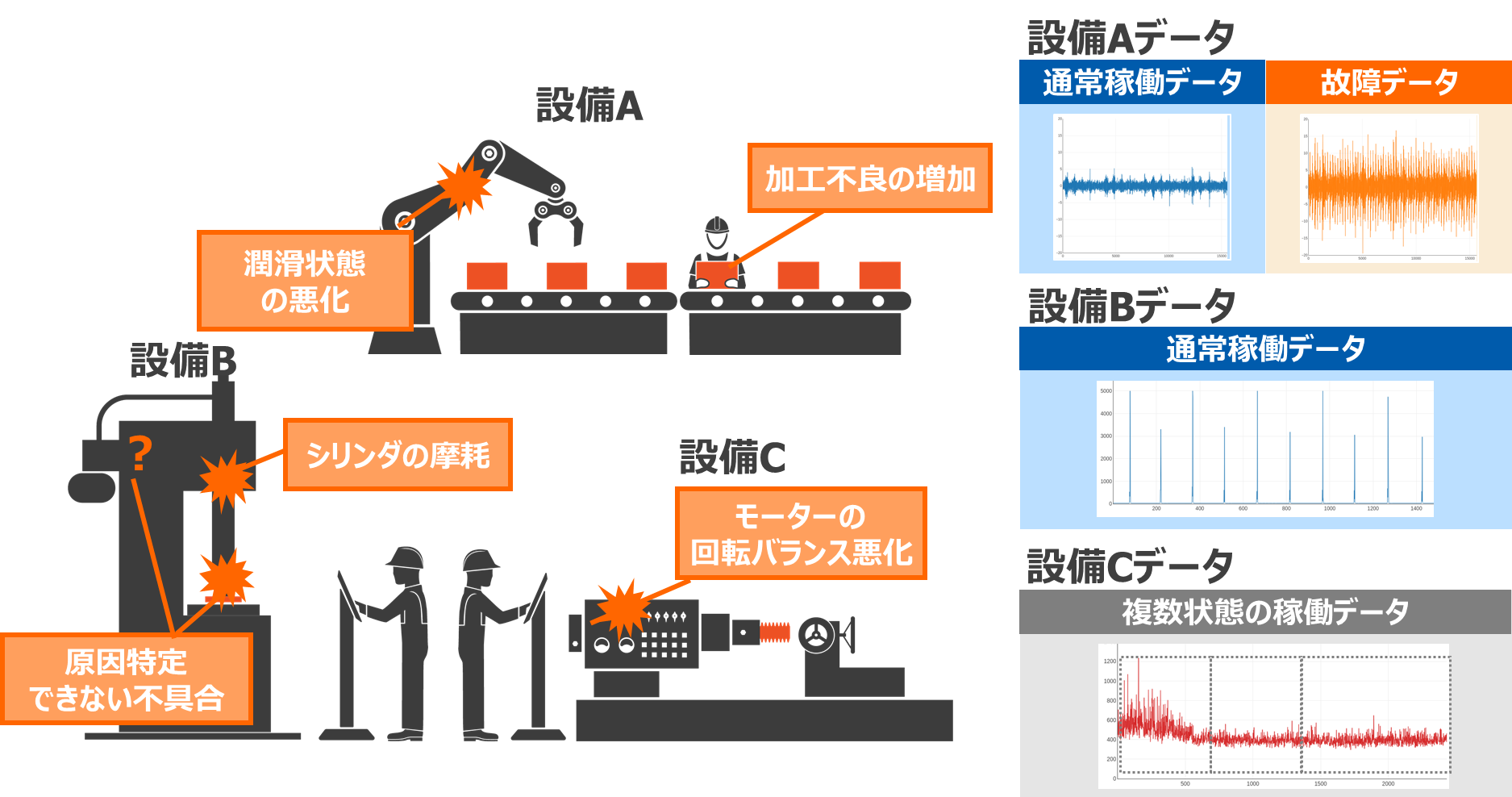
第2弾では、代表的な予知保全の例として、ベアリングの故障予知をテーマに取り上げました。しかし、実際の製造現場では、必ずしも1つの部品に着目すればよいわけではなく、複数の製造ラインや設備、部品があり、様々な故障や不具合が発生しているのではないでしょうか。
また、各設備の稼働状態も多様であるため、収集できるデータも多様です。必ずしも通常稼働時と故障時のデータがあるとは限らず、設備がいつ故障するかわからないために通常稼働時のデータしかない、もしくは収集データに複数の状態が混在しているような場合もあります。
つまり、ある1部品に対して1つのテーマがあるのではなく、多様な設備やデータ特性に対して複数のテーマが存在するのが、実際の製造現場です。
■多様な設備 × 多様なデータ特性
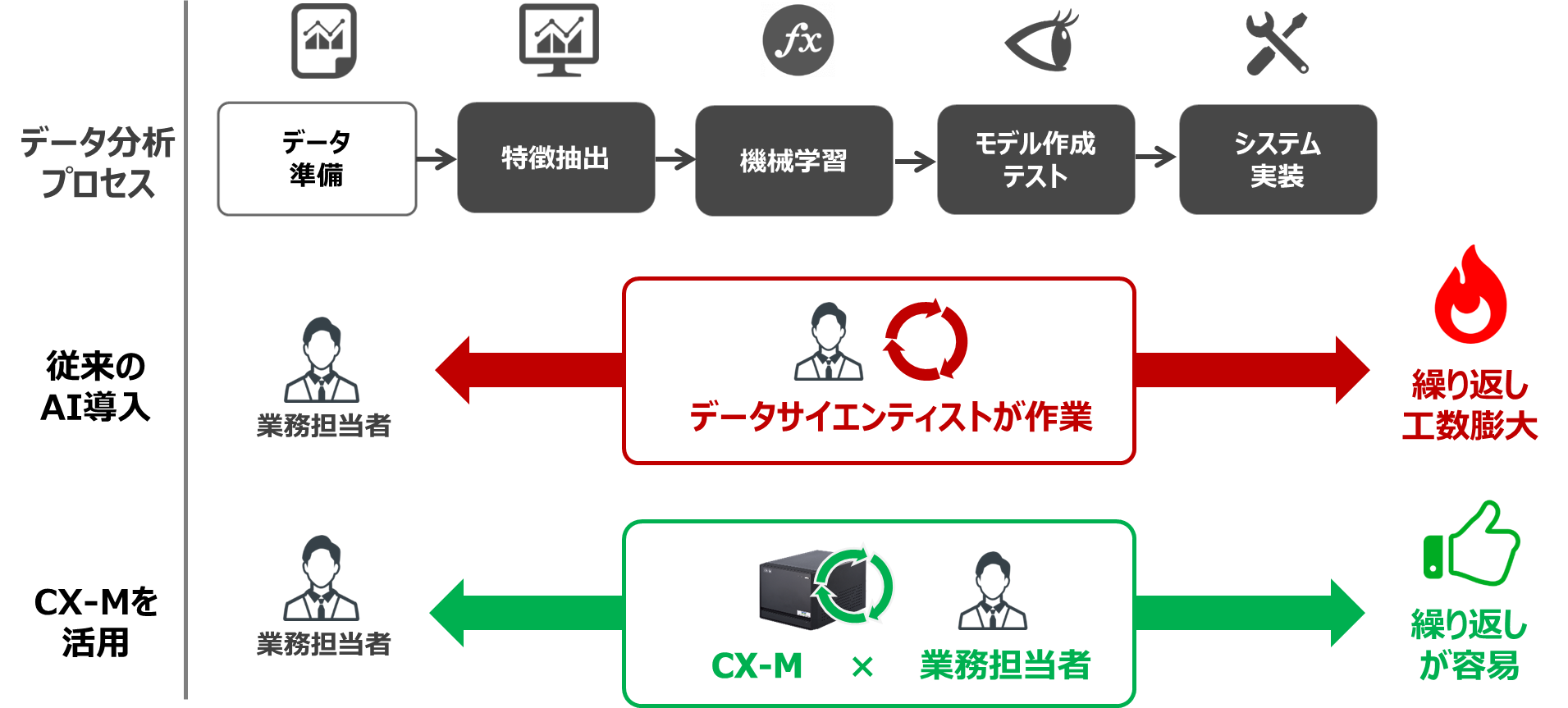
機械学習のデータ分析では、扱うデータの特徴を捉えることが重要であり、「特徴抽出」と「機械学習」のアルゴリズムの選択がポイントです。アルゴリズムにも様々な種類がありますので、精度の高いAIのモデルを作成するには、アルゴリズムの選定と検証、更にシステム実装と最適化をトライ&エラーを繰り返しながら進める必要があります。
■データ分析プロセスは繰り返しの連続
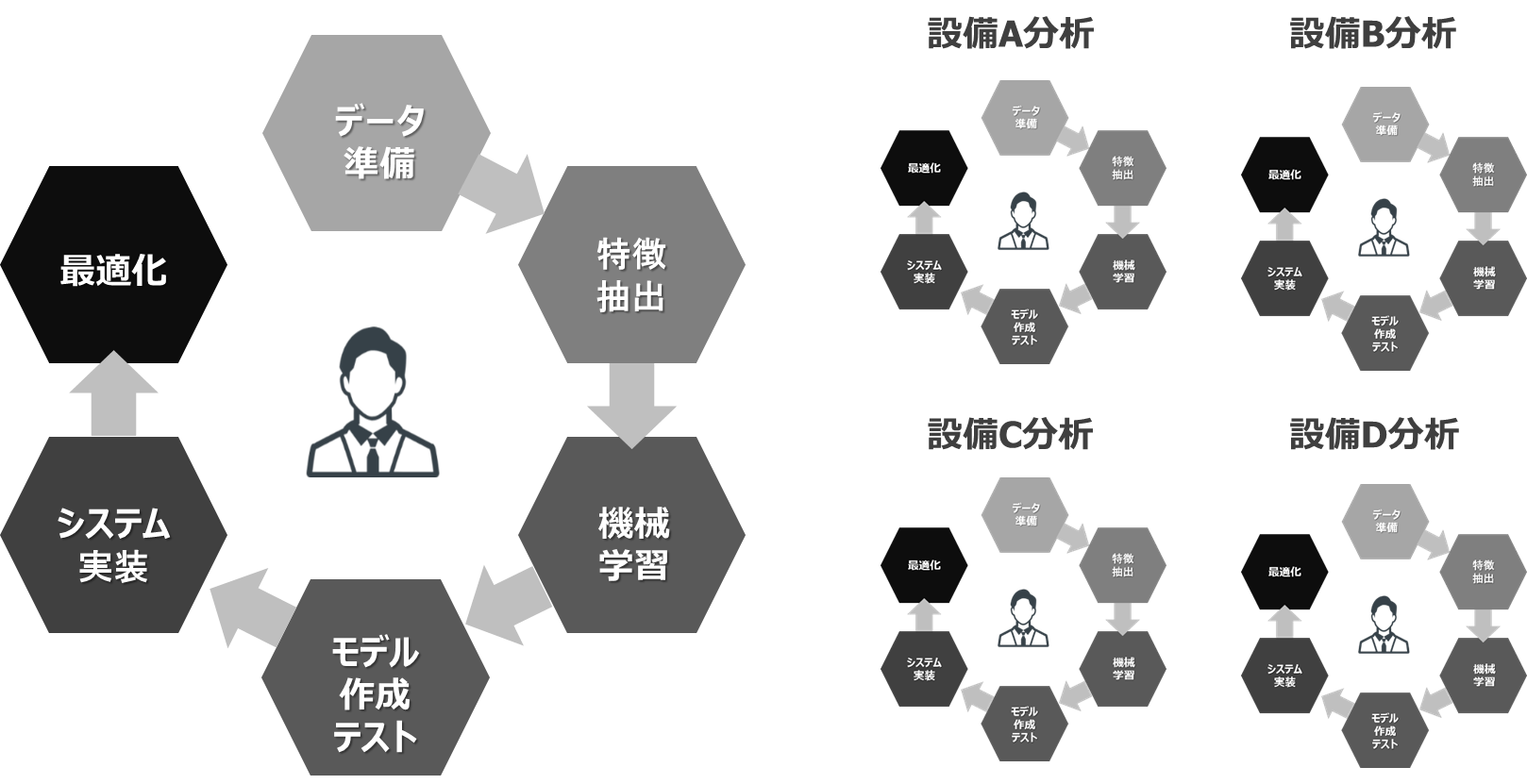
第2弾のデータ検証も、一部は弊社のデータサイエンティストによって、これまでの知見を元に複数のアルゴリズムから最適なものを選択し、前述のプロセスを繰り返した結果をご紹介しています。
これらを実際に行う場合、数ある設備やデータの特性、テーマの分だけ、このプロセスを繰り返す必要があります。
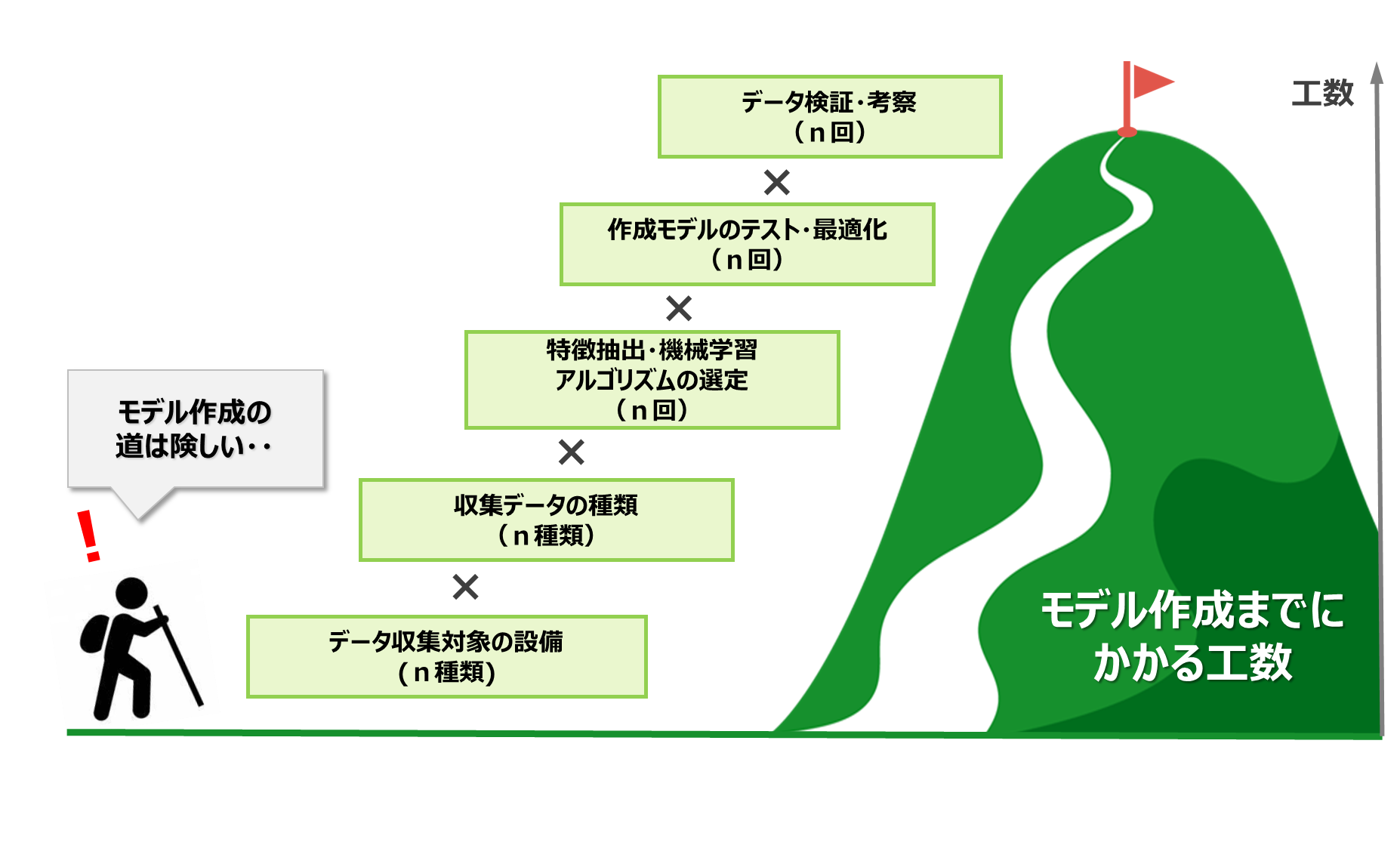
このように、現実に高精度なモデルを作成しようとすると、単なる作業プロセスの積み上げではなく、現場による複数の要素とデータ分析プロセスの繰り返しによって作業が倍増していきます。つまり、「人による作業工数」が膨れ上がり、実現への壁となります。

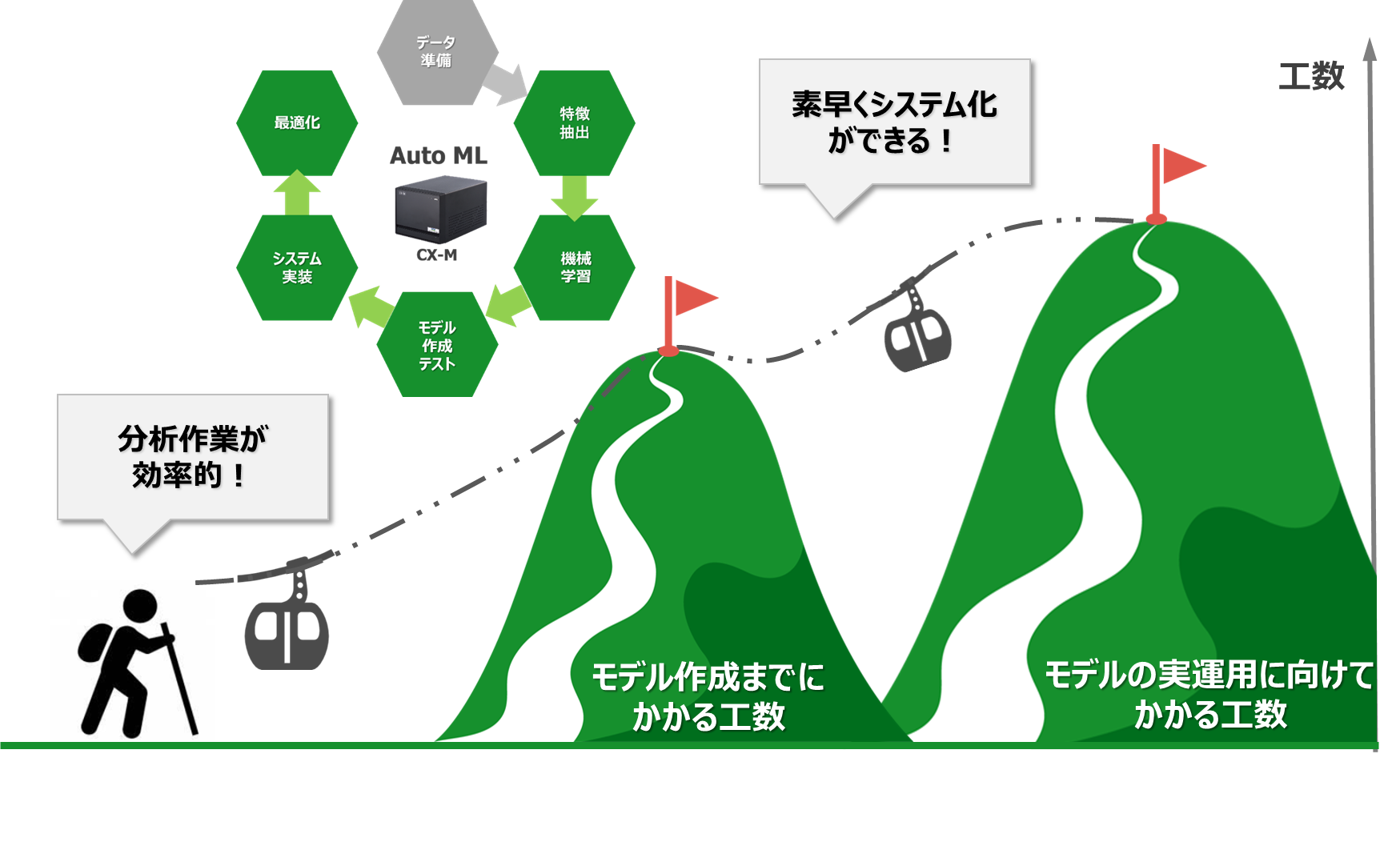
実は、このような試行錯誤を経て高精度のモデルが完成した後にも、もう1つの壁があることをご存じでしょうか?それは、モデルの実運用への壁です。
第2弾のデータ検証も、高精度なモデルを「作成」できるかどうか?という点までを検証した内容でした。しかし、実際の製造現場へのAI導入は、モデルを作成して終わりではなく、作成したモデルを現実の運用業務に乗せることができて初めて完了します。
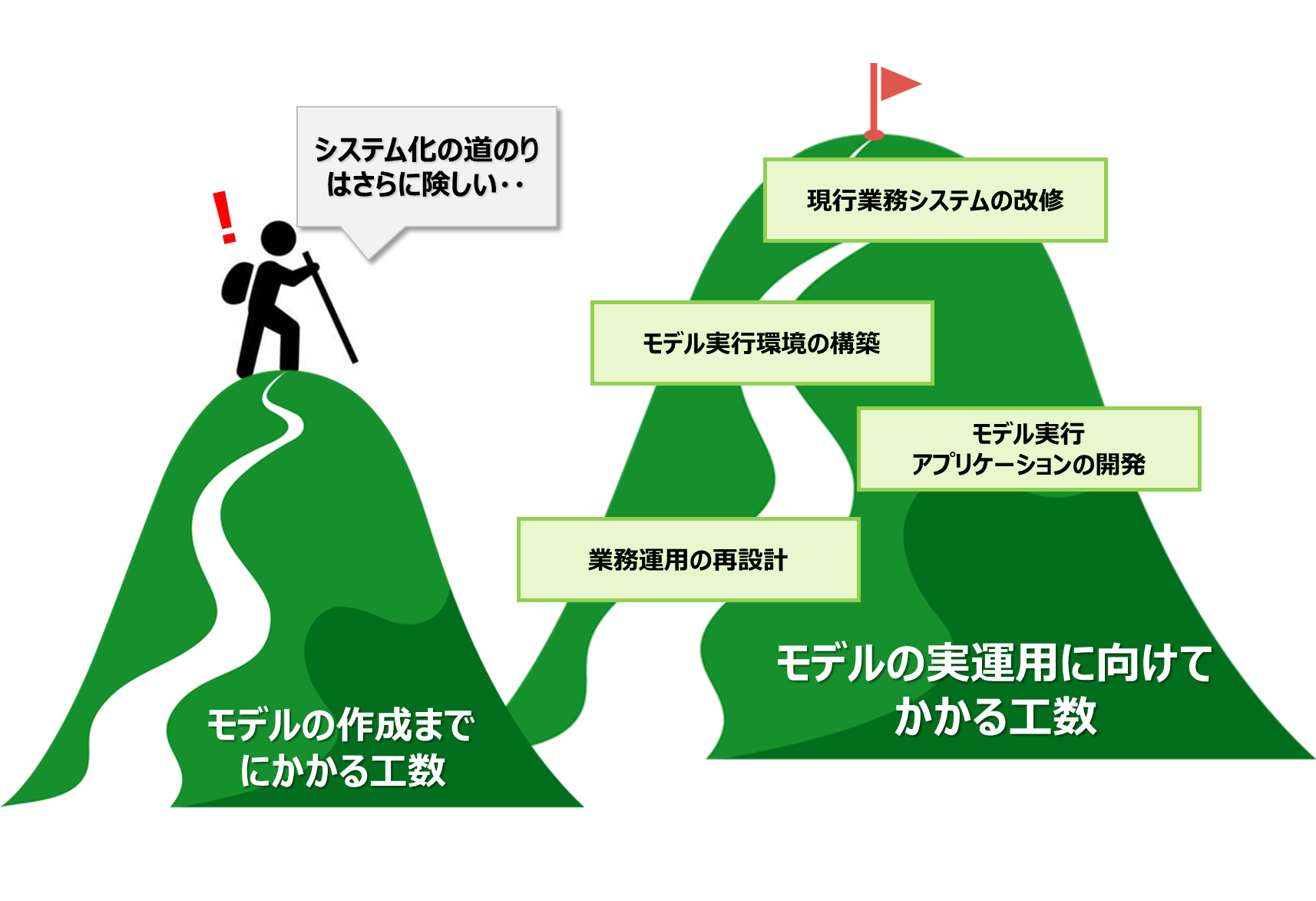
実運用に向けては、どのように収集した実稼働データを取り込みモデルを実行するのか、どのように業務でモデル実行結果を判断するのかを考える必要があります。更に、どのようなシステム構成で行うか、新たなシステム開発が必要か、どのような開発を行うかも検討する必要があります。
加えて、これらの検討範囲が広がるとステークホルダーも増えます。
データを収集したり、運用業務を進めるのは業務担当者です。しかし、業務担当者はデータ分析の知識があるとは限らないため、データサイエンティストが、前述のデータ分析プロセスを行うことが一般的です。実運用のためにシステム開発が必要な場合は、システムエンジニアやプログラマーの参画が必要となる場合もあります。
更に、これらを社外のIT事業会社に業務委託するケースも多いため、部門内外、社内外の多数の関係者が関わり、その間の調整工数も更に付加されます。
このように、実際にAIを導入しようとすると、「機械学習そのものにかかるコスト」以前に、「人による作業工数」が膨れ上がり、想定していたゴールにたどり着かない・・・ということが起こります。

このようなAI導入時の課題にどのように取り組めばよいでしょうか?
昨今では各社から様々なソリューションが提供されています。その選択肢の一つとして、弊社では「CX-M」という製品を展開しています。
CX-Mは、AI導入時の膨大な「人による作業工数」を極力減らし、業務担当者主体で容易に進められることを目指しています。
CX-Mには、収集したCSVデータの特性から、自動的にアルゴリズムを選定し、最適なモデルを作成する仕組みがあります。この仕組みによって、データサイエンティストが担っていたデータ分析のプロセスを、業務担当者自身が進めることができます。このようなモデル作成自動化の仕組みのことを「Auto ML」と呼びます。
■CX-Mがデータ分析にかかる工数を削減
CX-Mのアルゴリズムは、従来の機械学習を用いています。
実は、第2弾のデータ検証の内、従来の機械学習の結果は、非データサイエンティストがCX-Mでデータ分析をしたものでした。この結果からも、CX-Mが高精度のモデルをスピーディーに作成できることが分かります。
また、設備の通常稼働時のデータしか無い、または複数の稼働状態が混在している場合でも、CX-Mでモデルを作成できる機能があります。この機能により、様々な状態の設備でデータ分析を行うことができます。
加えて、モデルの実運用に向けても、CX-Mは作業工数削減の解決策を兼ね備えています。
CX-Mには、作成モデルを即実行できる実行モジュールの出力機能があります。この実行モジュールは、WindowsやLinux等の汎用的なプラットフォームに配置できます。その為、すぐにご利用の環境で実行したり、現行業務システムと連携したりすることができます。これにより、実運用に向けた運用設計やシステム開発工数を抑えることができます。
以上、AI導入時の課題への1つの解決策としてTEDのソリューションをご紹介しました。
今後も、CX-Mはアルゴリズムの更なる充実と機能の改善を進めていきます。
次期リリースのCX-M Ver. 5.3では新たな特徴抽出のアルゴリズムが加わり、2021年にはより完全なAuto MLの実現に向けて製品開発を進める予定です。


第1弾から第3弾を通して、従来の機械学習とディープラーニングの違いを切り口に、実際に製造業の現場で予知保全の領域でAIを活用するにはどのようなポイントや課題があるのかをお伝えしてきました。
弊社では、お客様が現場変革を確実に実践いただくことを目的に、弊社の経験・ノウハウ・暗黙知を体系化した「モノづくりDXステップガイド」を使い、お客様が社内関係者に説明可能な「計画書」の作成を可能にする支援プログラムをご提供しています。是非お気軽にご相談ください。

この記事を読んだ方におすすめ!
連載記事<予知保全に最適なAIとは? >
第1弾:「アルゴリズム選択の勘所」
第2弾:「データ検証による精度と処理時間の比較」

