- HOME
- 予知保全のためのデータ分析ステップとは
生産現場 予知保全・品質改善
予知保全のためのデータ分析ステップとは
現在多くの製造現場では、生産性向上のために様々なデータを収集し活用することで、現在直面している課題解決や新しい課題の発見に取り組んでいます。
しかし、こうした取り組みは、従来のモノづくり現場の知識や技術が必要なうえ、ITやデータサイエンスといった新しい知識・技術も求められるため、想定以上に多くの時間とコストがかかっている状況があります。
データ活用を加速するためには、そうした現場課題の解決が強く求められています。今回は、現在注目されている「予知保全」をテーマに、データ準備・分析に基本的なポイントをご紹介します。
予知保全システム実現のステップとポイント
予知保全は、工場やプラントにある設備状態をモニタリングし、不具合や異常の兆候を掴み、それを元に早めにメンテナンスを行い最適な稼働状態を保つ保全の手法です。こうした業務を現場に取り入れるには、各現場でビジネス課題を整理し実施する効果を見極め、どのような体制で対応していくかをしっかり議論することが重要です。
そのうえで技術的な実現性の確認を行う仮説検証を通して、システム化構想を立て構築、運用していくことが必要です。また、予知保全システムを構築するには、抑えるべきポイントが6つあります。以下の機能が連携し、継続的な監視業務を実現するシステムの整備が求められます。
予知保全システムを構築する6つのポイント
- センサやPLC等で設備データを集める「データ収集」
- 各設備のデータの実情を把握する「可視化」
- 通常状態からの変化度合を検知する「変化監視」
- データ特性から事象を特定する「状態診断」
- 監視結果を現場業務へ反映させる「通知」
プロジェクトステップ


予知保全に必要な6つのポイント

今回は、この6つのポイントの中で「データ収集」、「可視化」「データ分析」の部分にフォーカスをあて、具体的な取り組み方法やポイントを8つのステップに分けて説明します。
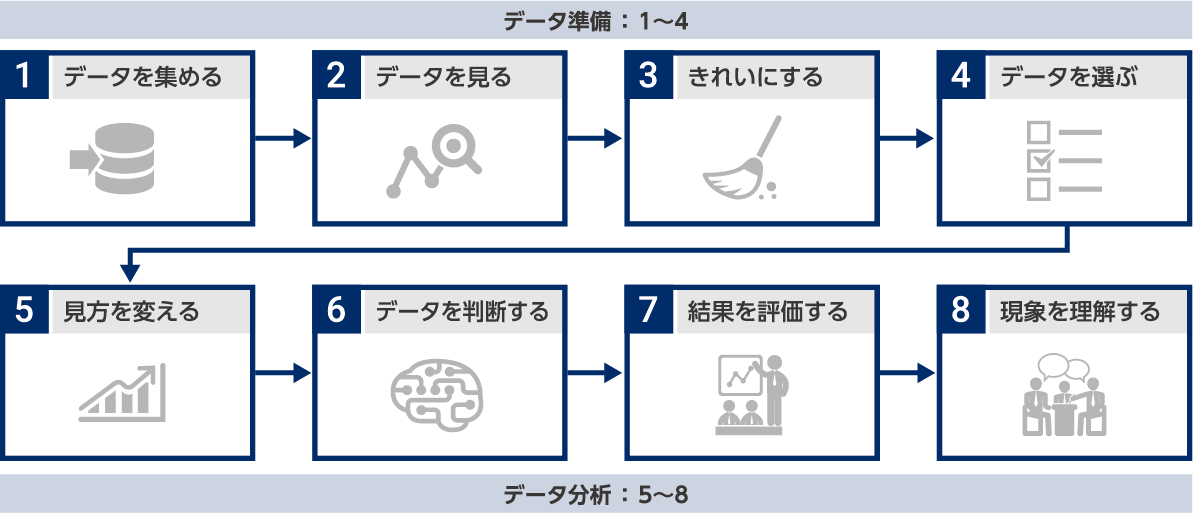
データ準備のポイント
1. データを集める:収集

2. データを見る:確認と可視化

● 欠損、特徴、異常値の有無を確認しデータ加工の必要性を判断する
● 観察すべき対象区間とそれ以外の区間の見分ける
● 異常値や状態変化を確認し正常・異常データの比較を実施する

3. データをきれいにする:除去・分割・正規化


4. データの選択:列選択・ラベル付


データ準備が終わった後のステップ
5. 見方を変える:特徴抽出


6. データを判断する:モデル作成


7. 結果を評価する:モデル評価


8. 現象を理解する:すり合わせ




関連製品


-

生産現場 予知保全・品質改善
予知保全も時短の時代!?異常検知の強化
-

生産現場 予知保全・品質改善
AIは「理解するもの」ではなく「捉えるもの」
-

生産現場 予知保全・品質改善
製造現場の改善プロセスをDX化する新手法とは
-

生産現場 予知保全・品質改善
装置の予兆を監視しリモートでサポートする【DXメンテナンス】 サービスとは
-

生産現場 予知保全・品質改善
製造現場のデータを一瞬でグラフ化!無料で簡単に使えるCSVファイル可視化ツールとは
-

生産現場 予知保全・品質改善
脱!データ活用迷子「データ活用の始め方を知る」製造業の課題解決に向けたモノづくりDX 計画作成講座
-

生産現場 予知保全・品質改善
設備診断に有効なAEセンサとは
-

生産現場 予知保全・品質改善
開発者が語る【CX製品誕生の歴史】「現場ですぐに使える」を形に異常検知・設備診断システム「CX-D」の開発秘話
-

生産現場 予知保全・品質改善
開発者が語る【CX製品誕生の歴史】製造業のデータ分析作業を変革 時系列データ自動分析マシン「CX-M」の開発秘話
-

生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極めるアルゴリズム選択の勘所
-

生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極めるAI導入の課題と解決方法とは
-

生産現場 予知保全・品質改善
【工場DX】予知保全に最適なAIを見極めるデータ検証で徹底比較した結果とは
-

生産現場 予知保全・品質改善
DXで生産ロスを改善する【データ活用術】データ収集課題の解決ポイントとは
-

生産現場 予知保全・品質改善
DXで生産ロスを改善する【データ活用術】プロジェクト目標設定と注意点とは
-

生産現場 予知保全・品質改善
DXで生産ロスを改善する【データ活用術】不良ロスを削減する設備データ活用
-

生産現場 予知保全・品質改善
DXで生産ロスを改善する【データ活用術】設備の動きをデータでとらえるコツとは
-

生産現場 予知保全・品質改善
DXで生産ロスを改善する【データ活用術】設備停止・性能ロスを削減する予知保全
-

生産現場 予知保全・品質改善
CSVデータの可視化だけでは終わらせない!時系列データ活用術