- HOME
- インテル® OpenVINO™ を活用したAI医用画像診断
設計 設計・製造受託
インテル® OpenVINO™ を活用したAI医用画像診断
近年、モダリティで撮影した医用画像からAI(ディープラーニング)による疾患診断を行う研究および、医療機器メーカーによる診断ソリューションの提供が急速に進められています。
ディープラーニング推論の実行ハードウェア環境は演算の処理能力要求が高く、外部アクセラレータでの実行が一般的です。しかしハードウェア機器追加によるコストアップ、消費電力、長期供給といった面で課題があります。
今回の特集記事ではエッジでのディープラーニング推論を高速化する無償ツール インテル® OpenVINO™ を使用し、外部アクセラレータを使わない医療画像診断デモとベンチマーク結果をご紹介します。
目次


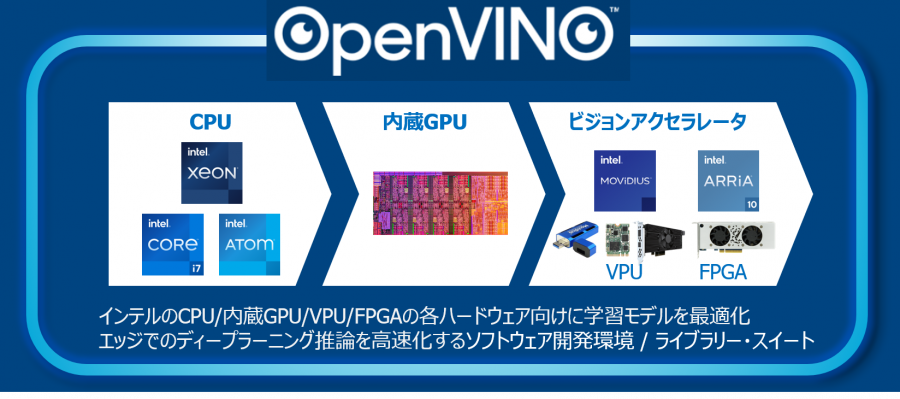
インテル株式会社により無償提供されているディープラーニング推論向けの開発ツールです。
特徴
・インテルのCPU、GPU、アクセラレータに対して、推論処理の性能を最適化しディープラーニング推論のパフォーマンスを大きく向上
・異なるアーキテクチャに対して同一のAPIで動作が可能
・コスト、消費電力、パフォーマンスなど目的により柔軟なエッジコンピューティングのシステム構成が選択可能
・年3-4回ごとのバージョンアップし機能追加や性能向上があり、組み込み向けにLong Term Support バージョンも提供
・様々なOSに対応 (Windows , macOS , Ubuntu , CentOS , Yocto )

OpenVINO™ 向けには多数の学習済みモデルが用意されていますが、今回はBrain Tumor Segmentation Challenge (BraTS) 2018向けに作成された、U-netネットワークのセグメンテーションモデルを使用します。
OpenVINO™ でディープラーニング推論を実行するには、通常、CaffeやTensorFlowといったフレームワークで作成した学習済みモデルをOpenVINO™ 用の中間表現フォーマットに変換する手順が必要です。変換にはModel Optimizerを使用しますが今回のデモはインテルより提供されている学習済みモデルを使用していますので変換の手順はスキップできます。
このモデルを医療の現場を想定しPoint-of-Care向けのパネルPCで実行、推論時間を確認します。デモの環境をまとめると以下の様になります。
- PC:ADVANTECH製 POC-W243
CPU:インテル® Core™ i5-6300U プロセッサー
Core(Thread):2(4)
CPU Clock:2.4(3.0) GHz
GPU:インテル® HD グラフィックス 520
Memory:4GB (DDR4 2133)
OS:Ubuntu18.04 LTS
Tool:インテル® OpenVINO™ 2020.3LTS
Model:Custom Pretrained Model
また、弊社では今回の記事で使用したPCをはじめ、多くの産業用PC取り扱いも行っております。
お問い合わせはこちらから
モデルこちらからダウンロードいただけます。モデルと併せて提供されるサンプルコードとMRI画像(Rawデータ)を使用しデモを構築しました。
産業用デモイメージ
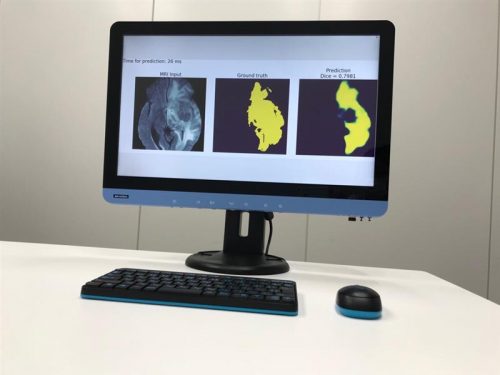
※実際のサンプルコードでは診断結果の動的な連続表示はされませんがPythonのサンプルコードを編集し実行しています。
- 表示される結果について
MRI Input : MRIの画像データ
Ground truth : セグメンテーションの精度評価で使用するグラウンド トゥルース
Dice : Dice スコアによるセグメンテーションの精度評価結果
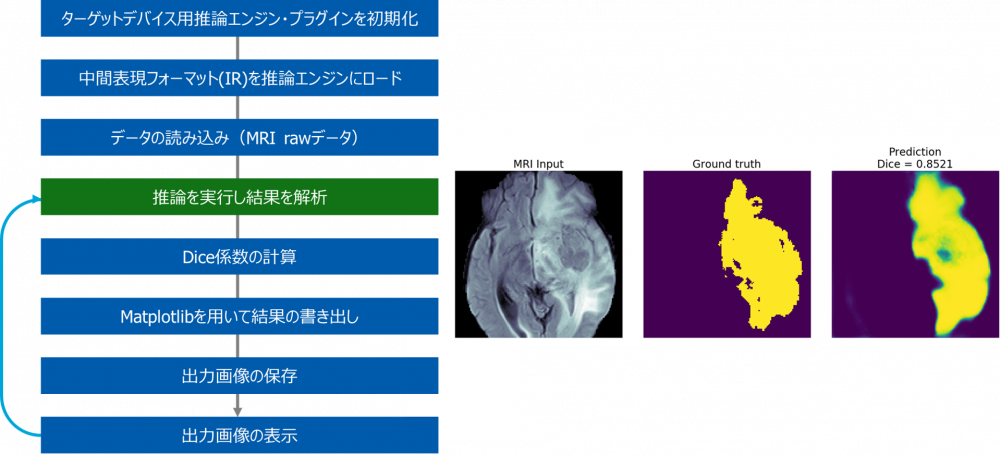
- サンプルコードコードの動作
以下はサンプルコードの動作を表したものです。「推論を実行し結果を解析」の箇所でOpenVINO™ による推論が実行されます。OpenVINO™ では推論の実行ハードウェア指定は実行時に引数変更だけで指定できますのでCPUと内蔵GPUの切り替えは容易に行えます。
- ベンチマーク
推論処理の時間を測定する方法はいろいろありますが、今回はインテルより推奨されているOpenVINO™ に付属のベンチマークアプリケーションを使用しました。このアプリケーションは中間表現フォーマットのモデルと実行ハードウェア(CPU,GPU等)、精度(FP16,FP32等)を指定するだけで簡単に最適条件でのパフォーマンス評価が可能です。実行結果を示します。
| Infrelense Device | Model Optimization | Latency(ms) | fps |
|---|---|---|---|
| CPU | FP32 | 257.2 | 15.9 |
| GPU インテル® HD グラフィックス 520 |
FP32 | 177.2 | 22.9 |
| FP16 | 106.7 | 37.9 |
1スライスあたりの平均処理時間
CPUはFP16に対応していませんが内蔵GPUを使用した場合、FP32でもCPUリソースでの推論より高速に動作することが確認でき、FP16を使用した場合更に推論の処理速度(fps)を向上しました。
また、GPUリソースを使用することでCPUは他のアプリケーション動作にパワーを割くことが可能となります。内蔵GPUはエンコード等で使われますが通常の用途では処理が空いていることが多いため推論処理での使用を検討する余地が十分にあります。

今回の記事では、インテル® OpenVINO™ を活用した医療画像診断デモとベンチマーク結果をご紹介しました。OpenVINO™ による最適化と内蔵GPUの活用により、エッジでのディープラーニング推論の高速化の事例をご覧頂けたかと思います。今回使用しているCPU Skewは、2015年リリースの第6世代 インテル® Core™ プロセッサーで、最新のCPU Skewを選択することで更なるパフォーマンス向上が行えます。次回以降は最新のCPU Skewを使用した場合など様々なケースをご紹介していきたいと思います。このようなお悩みをお持ちの方は是非ご相談ください。
- プラットフォームの検討をしている
- エッジでのディープラーニングを検討している
- 推論パフォーマンスを向上させたい
また、弊社では今回ご紹介差し上げたディープラーニング以外にも医療機器の開発実績も多数ございます。オンラインサロンも開設しておりますので、気軽にお問い合わせください。
Intel、インテル、Intel ロゴ、その他のインテルの名称やロゴは、Intel Corporation またはその子会社の商標です。
この記事を読んだ方におすすめ!
医療機器への受託開発の取り組み



