- HOME
- 【画像処理マスターへの道】 AIを使いこなす鍵は、“弱点の補完”にあり!
装置メーカー 画像処理ソフト
【画像処理マスターへの道】
AIを使いこなす鍵は、“弱点の補完”にあり!
こんにちは、ファーストの担当Uです!本記事は、画像処理に関連するさまざまな情報をお届けするシリーズ記事です。
前回は実は身近で使われている画像処理の例をご紹介しました。今回は、AI画像処理の沿革から使いこなすための考え方とその実例をご紹介していきます。
画像処理におけるAIトレンドの歴史
ここ最近のAIといえば、「ChatGPT」や「Copilot+PC」、「Apple Intelligence」、「Googleフォトアプリ」の消しゴムマジックなどですが、改めて画像処理業界のAI研究の歴史を簡単にご紹介します。
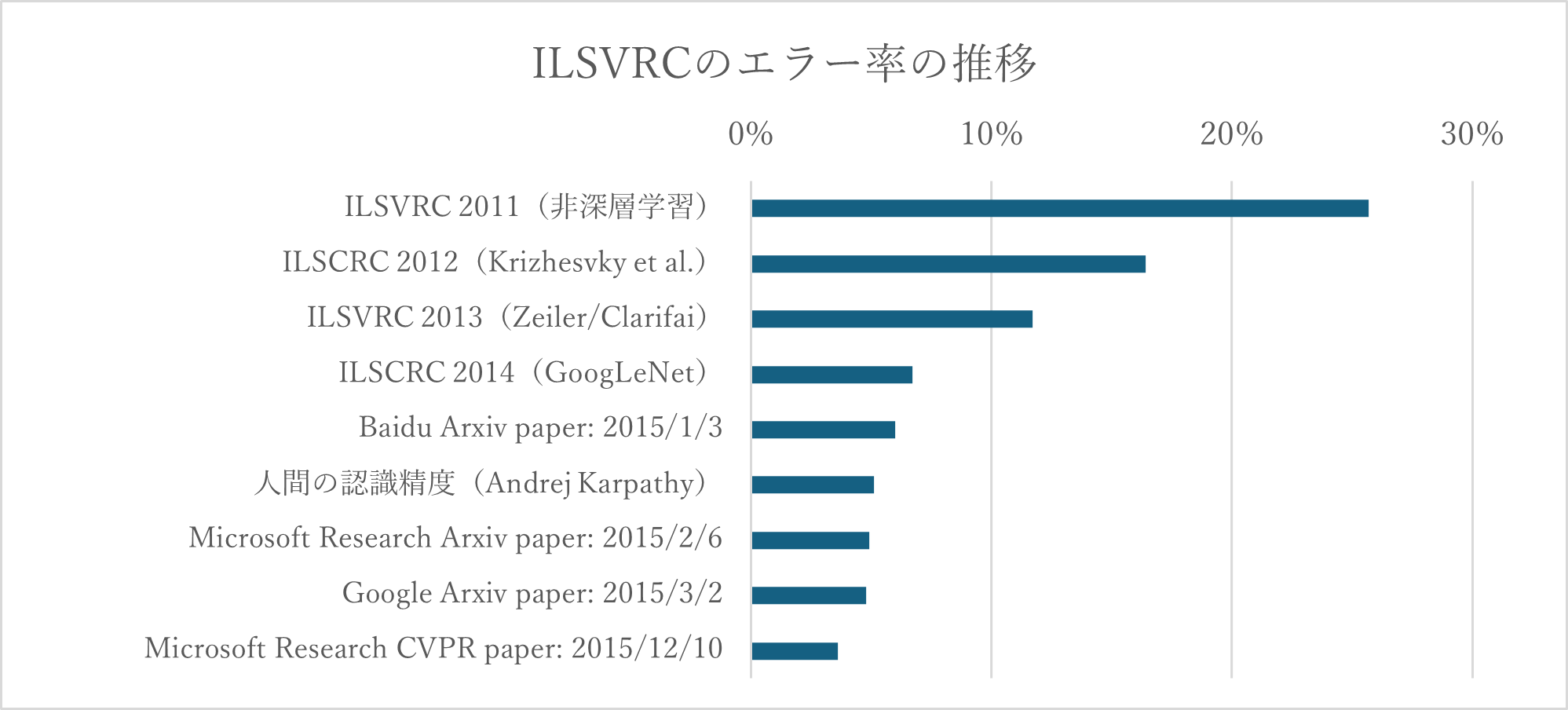
ブレイクのきっかけは、2012年のILSVRC(ImageNet Large Scale Visual Recognition Challenge、大規模画像認識の競技会)です。2011年までは非深層学習(ルールベースのみ)の手法がトップで、エラー率は25.7%程度でした。
ところが、2012年に深層学習を取り入れた手法がエラー率16.4%でトップとなり、それまでは構築したアルゴリズムを人手でチューニングして0.1%の更新を競っていたところに、約10%の大幅な更新となり、研究者に衝撃を与えたのでした。その後の深層学習の進歩は目覚ましく、2015年にはエラー率4.9%を達成すると、競技の内容を目視で行うと人間はどの程度間違えるかの調査の結果は5.1%だったという研究を踏まえて、AIが人間を越えたなどともてはやされたものでした。
ILSVRCはその画像に何が写っているか(例えば、犬の画像や猫の画像など)を見分ける画像分類の競技会でしたが、それだけでなく、FA用途の画像処理に必須な機能である以下のような技術も発展しました。
- 画像分類:画像全体を見て、その画像の種類を分類する(例:「これは犬の画像」「これは猫の画像」)
- 物体検出:特定の物体の位置と大きさを見つける(例:「この画像のここに犬がいる」と枠で囲む)
- セグメンテーション:画像内の物体の領域を塗り絵のように抽出する(例:「犬の部分だけを正確に塗りつぶす」)
こうした技術の発展に伴い、多くのデータセットが整備され、最高精度(SOTA; State of the Art)を競い合う環境(Papers With Codeなど)が熟成してきました。
ここ数年の研究者の関心は、「ChatGPT」を始めたとした生成AIに移っている印象ですが、マルチモーダル(例:自然言語と画像のような異なるモーダルの組み合わせ)としての画像への興味は引き続き高く、特に自然言語での指定による画像生成や、ゼロショット(事前学習のみで追加学習することなく)で画像から領域を抽出する技術(SAM; Segment Anything Model)などの発展には目覚ましいものがあります。
AIをうまく使いこなすアプローチ
当社でも、AIプラットフォームとして、画像分類とアノマリー検出の単体機能から始め、その多視点版やセグメンテーション、物体検出などの機能追加を行うなど、AI画像処理の活用を進めています。
AI画像処理の発展には目を見張るものがありますが、AIの得意不得意(特にFA用途での運用・保証の難しさ)を踏まえると、実際に導入してみた実感としても、必ずしもすべての画像処理をAIに置き換えることは最適解ではないと考えています。
そこで、適材適所で使い分ける「ルールベース×AI」をコンセプトとして、実案件でも常に、まずはルールベースで実現できる方法の模索から始めています。

ユースケース
AI導入までの道のり
リサイクル業界での選別作業の自動化におけるAI導入までの道のりの実例をご紹介します。

- ご相談内容:混ざってしまっているプラゴミを選り分ける作業の自動化
- 画像処理の役割:家庭ゴミがゴミ袋から取り出され、コンベアに広げられた状態から、プラスチック製品、特にビニール袋を見つけ出すこと
まず初めに人は何を見て何を基準に判断しているかを考えます。人の視覚はとても優秀です。そのロジックを言葉で表現してみることからルールベースの画像処理アルゴリズムの検討は始まります。
本件でも、ビニール袋の色や形状は個体ごとに異なるにもかかわらず、人は見ればおおよそ分かります。では何を見てどのような根拠で判断しているかを言葉で表現しようとしてみると、素材のテクスチャの見え方がビニールらしい光り方をしていることではないかと考えられます。
このテクスチャの情報をテクスチャ特徴量(※1)として数値化し、ビニールらしい光り方に対応する傾向を見出すことができれば、人の視覚をルールベースの画像処理アルゴリズムとして再現できます。
そこで検討の初期段階ではテクスチャ特徴量に着目して解析を試みました。しかしながら、得られた特徴量を観察しても、サポートベクターマシンなどの古典的な機械学習(※2)を試してみても、良い結果を得ることはできませんでした。
AI(深層学習)の登場以前であればこの時点で断念となっていましたが、当時は物体検出のYOLO(※3)シリーズが登場して数年の頃でした。
物体検出とは画像の中から人間や自転車、犬などをそれぞれに見つけることができる技術です。例えばさまざまな犬種を学習しておくことでどのような犬でも見つけられるようになるなど、見え方のバラツキの大きいものを学習することで共通する特徴を自動的に抽出できるようになると考えられます。色や形状が不定なのに人はなぜか判断できるビニール袋らしさという難しさを解決できそうです。
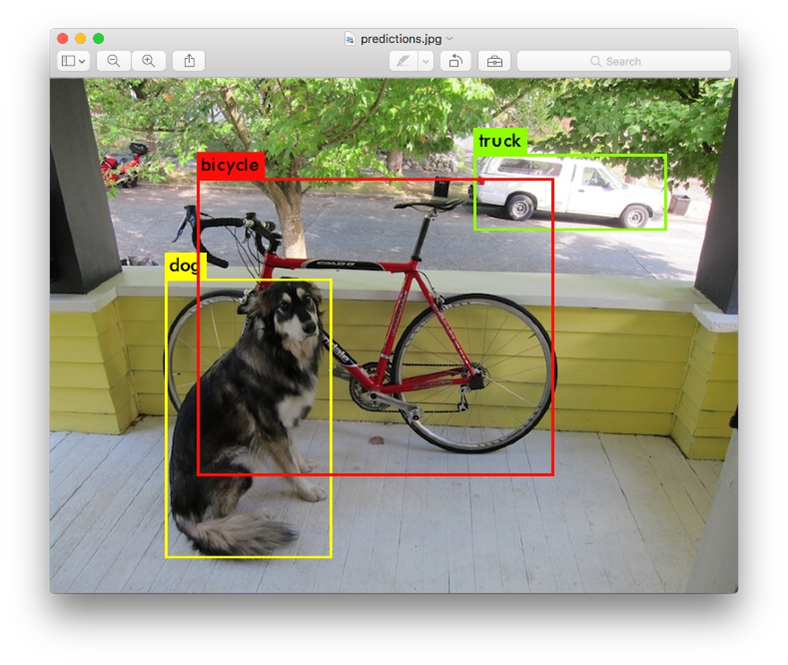 出典:https://pjreddie.com/darknet/yolo/
出典:https://pjreddie.com/darknet/yolo/
早速評価環境を整えて実験してみたところ、当たりテスト用の少ない画像だけの学習でも6-7割前後は検出できるようになりました。
この結果をお客様にご報告の上、画像を撮りためて検出対象のすりあわせを行うN増し評価を重ねていき、最終的には約2万枚の画像を学習することで85%程度の検出率を実現することができました。
特に、検出対象とすべきかのすりあわせではお客様に多大なるご協力をいただき、我々が申し上げるのは僭越ですが、装置が動き出したときには戦友のような気持ちで達成感を分かち合えました。
画像の色合い(RGBの各値)のヒストグラムから平均値と分散、歪度(Skewness)、尖度(Kurtosis)を求める方法や、同時生起行列を用いて周辺との色情報との関係をエントロピーやエネルギー、慣性、局所一様性を求める方法などがあります。当社画像処理ライブラリのC/C++言語向けのFIEライブラリでは「画像統計量 -> テクスチャ解析」にこれらの機能はまとめられています。
近年はAIというと専ら深層学習を指していることがほとんどですが、それ以前にも人間の思考を模倣しようというモチベーションで機械学習の研究は行われていました。例えば、ある特徴量が10以上であればAであるという単純な判定や、2つの特徴量がy=2x+5の直線よりも左上にあったらAである程度の判定であれば、特徴量をプロットして観察することで人間が設計できます。しかし、境界線が直線でなくて曲線になるときの曲線の方程式の推定や、特徴量が3つ以上の観察(2次元のグラフに描けない)などは人間の限界を超えてきます。これらの課題を乗り越えるためにサポートベクターマシンやナイーブベイズ分類器などが研究開発、実用されてきました。当社画像処理ライブラリのC/C++言語向けのFIEライブラリでは「機械学習」にこれらの機能がまとめられています。
You Only Look Onceの頭文字を取ったAI(深層学習)による物体検出の手法の一つです。他の手法に比べて検出精度を比較的保ったまま速度を大幅に向上させたことで注目されました。最初のバージョンの開発者は離れてしまいましたが、その後も改良が続いています。2024年5月にはバージョン10に相当するYOLOv10が発表されました。当社AIプラットフォームではライセンスに配慮してYOLOXとYOLOv7の機能を搭載しています。
AIをルールベースで補完
類似の別案件からAI画像処理をルールベースで補完した実例をご紹介します。
- ご相談内容:吸着ではなく、挟み込むロボットハンドを使用してのピッキング
- 画像処理の役割:対象物の検出とその角度計測
改めて、人は何を見て何を基準に判断しているかを考えます。人は対象物の外形を頼り、その長手方向として角度を認識していそうです。
ルールベースの画像処理アルゴリズムとしては、対象物の領域をブロブとして取得することができれば、その特徴量の一つの慣性主軸方向として角度を計測することができます。
そこで 、AIで見つけた対象物の周辺のみに限定してルールベースの二値ブロブ解析を試みました。画像全体から対象物を見つけることにはルールベースの画像処理だけでは力不足でしたが、対象物の周辺のみに限定できればルールベースも十分に有効で、実際にロボットで挟んでピッキングできることを確認できました。

橙線:ルールベースで計測した対象物の角度
AIで対象物の位置だけでなくて角度も含めて学習する方法もありますが、学習データを作成する負荷が大きくなってしまいます。角度の計測はルールベースで実現することで運用負荷の増加を最小限にとどめながら、角度計測を追加することができました。
まとめ
AI画像処理は、ルールベースでは実現できないことが実現できてしまう凄さがある一方で、説明可能性と判定の調整に再学習が必要なこと、そもそも大量の学習データの準備に時間と手間が掛かることが弱点でもあります。
そこで、すべてをAIのみで実現するのではなくて、ルールベースの画像処理アルゴリズムで不足するところをAIで補うことで相互の弱点を補い合うというのがAIをうまく使いこなすアプローチです。
今回は実案件でのアルゴリズム構築の考え方からAIを活用する流れ、更に逆にAIの不足するところをルールベースで補った実例をご紹介しました。
当社AIプラットフォームはルールベースの画像処理にAIを追加しやすいように設計している他、AI以前からの画像処理メーカーとしてルールベースの画像処理のノウハウもございます。ぼんやりとしたやりたいことベースでも構いませんので、お気軽にご相談いただけましたら幸いです。
次回は、画像処理の実行環境であるハードウェア製品の新しいファミリーのご紹介を予定しています。

※画像処理ライブラリ 資料一式(カタログ/商品説明書/AI活用事例集)
-

装置メーカー 画像処理ソフト
【画像処理マスターへの道】実は身近で使われている画像処理
-

生産現場 計測・検査
開発者に聞く!AI活用による目視検査の自動化
-

生産現場 計測・検査
開発者に聞く!広範囲で迅速な検査を可能にする三次元塗布検査装置とは
-

装置メーカー 画像処理ソフト
【画像処理マスターへの道】AIを使いこなす鍵は、“弱点の補完”にあり!
-

装置メーカー 画像処理ハード
【画像処理マスターへの道】画像処理装置に新しいファミリーが増えています!
-

装置メーカー 画像処理ソフト
【画像処理マスターへの道】次の一歩を手前の一歩から考える~分割点灯の照らす世界~
-

装置メーカー 画像処理ソフト
【画像処理マスターへの道】研究トレンド最前線 ~ブレイク直前の技術を先取り!~
-

装置メーカー 計測・検査・位置合わせ
【画像処理マスターへの道】高精度位置決め実験レポート~超精密ステージで1μmの壁に挑む!
-

装置メーカー 画像処理ソフト
【画像処理マスターへの道】ライブラリ新機能のご紹介~ピント合わせのお悩み解決~
-

生産現場 計測・検査
【画像処理マスターへの道】高精度位置決めリベンジ報告~めざせ、サブミクロンを1回で~